对于大表的统计信息收集,我们可以加degree参数,使得扫描大表的时候,进行并行扫描,加快扫描速度。
但是这在收集的时候,还是进行一个表一个表的扫描。并没有并发的扫描各个表。在oracle 11.2.0.2之后,就有了一个参数,可以并发扫描表(或者分区),这就是CONCURRENT参数。你可以通过
|
1 |
SELECT DBMS_STATS.get_prefs('CONCURRENT') FROM dual; |
看到你的数据库是否启用了CONCURRENT收集统计信息。
开启方式为:
|
1 2 3 4 |
SQL> begin 2 dbms_stats.set_global_prefs('CONCURRENT','TRUE'); 3 end; 4 / |
开启concurrent之后,收集统计信息就会以并发的形式进行,会并发出多个job进程。
其收集方式如下图:
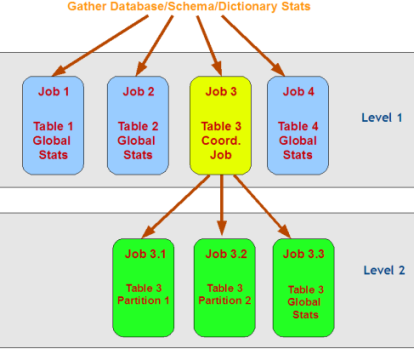
从测试结果看,启用concurrent的收集统计信息速度对比:
schema级别的收集,XXX_SCHEMA下有400个多segment,大约20多GB:
默认:
|
1 2 |
exec dbms_stats.gather_schema_stats(ownname => 'XXX_SCHEMA'); --263秒 |
开启8个并发:
|
1 2 |
exec dbms_stats.gather_schema_stats(ownname => 'XXX_SCHEMA',degree => 8); --95秒。 |
开启concurrent+8个并发:
|
1 2 3 4 5 6 |
begin dbms_stats.set_global_prefs('CONCURRENT','TRUE'); end; exec dbms_stats.gather_schema_stats(ownname => 'XXX_SCHEMA',degree => 8); --61秒 |
database级别的收集:(600多G数据,9万多个segment)
默认:
|
1 2 |
exec sys.dbms_stats.gather_database_stats; --9小时 |
开启concurrent+8个并发:
|
1 2 3 4 5 6 7 |
begin dbms_stats.set_global_prefs('CONCURRENT','TRUE'); end; exec dbms_stats.sys.dbms_stats.gather_database_stats(degree => 8); --4小时 |
需要注意的是:
1. 用concurrent收集统计信息,需要收集统计信息用户具有以下权限:
CREATE JOB
MANAGE SCHEDULER
MANAGE ANY QUEUE
即使是该用户具有了dba角色,也还是需要显式授权上述权限。
不然执行job的时候,可能会报错
ORA-27486 insufficient privileges和ORA-20000: Statistics collection failed for 32235 objects in the database
2. concurrent不能控制多少的并发度,所以如果数据库的初始化参数job_queue_processes设置的太高,(注意,在11.2.0.3之后,这个值的默认值是1000,所以就可能并发出1000个job。)
如在测试时,某测试库设置了60个job_queue_processes的时候,数据库中就会并发出60个job来收集统计信息。此时的top情况,可以看到CPU的user部分基本已经在90%以上了。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
top - 11:31:08 up 118 days, 19:28, 2 users, load average: 30.65, 28.13, 25.64 Tasks: 728 total, 50 running, 678 sleeping, 0 stopped, 0 zombie Cpu(s): 91.7%us, 7.5%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.7%si, 0.0%st Mem: 16467504k total, 16375356k used, 92148k free, 119896k buffers Swap: 6094844k total, 2106168k used, 3988676k free, 8952852k cached PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 19295 ora 20 0 8856m 154m 119m R 22.9 1.0 0:01.44 ora_j030_mydb12 18503 ora 20 0 8856m 583m 548m R 21.0 3.6 0:25.02 ora_j032_mydb12 19042 ora 20 0 8856m 332m 297m R 21.0 2.1 0:09.21 ora_j026_mydb12 19162 ora 20 0 8856m 273m 238m R 21.0 1.7 0:05.51 ora_j020_mydb12 19203 ora 20 0 8856m 198m 164m R 21.0 1.2 0:02.66 ora_j035_mydb12 19211 ora 20 0 8856m 243m 208m R 21.0 1.5 0:04.03 ora_j024_mydb12 18550 ora 20 0 8856m 526m 491m R 20.0 3.3 0:21.06 ora_j033_mydb12 19009 ora 20 0 8856m 305m 271m R 20.0 1.9 0:07.84 ora_j031_mydb12 18792 ora 20 0 8857m 502m 467m R 19.6 3.1 0:18.23 ora_j022_mydb12 19199 ora 20 0 8856m 204m 169m R 19.3 1.3 0:03.31 ora_j025_mydb12 19137 ora 20 0 8857m 401m 367m R 19.0 2.5 0:06.67 ora_j011_mydb12 14518 ora 20 0 8857m 3.7g 3.6g R 18.3 23.3 1:25.49 ora_j003_mydb12 ... 19128 ora 20 0 8857m 257m 222m R 17.0 1.6 0:04.57 ora_j034_mydb12 19255 ora 20 0 8856m 208m 173m R 17.0 1.3 0:02.79 ora_j000_mydb12 19065 ora 20 0 8856m 437m 402m R 16.7 2.7 0:09.31 ora_j001_mydb12 19073 ora 20 0 8856m 262m 227m R 16.7 1.6 0:05.53 ora_j038_mydb12 19195 ora 20 0 8848m 246m 215m R 16.7 1.5 0:04.21 ora_j004_mydb12 19112 ora 20 0 8857m 297m 262m D 16.4 1.9 0:06.68 ora_j017_mydb12 19299 ora 20 0 8856m 155m 120m R 16.4 1.0 0:01.21 ora_j037_mydb12 12088 ora 20 0 8872m 1.4g 1.3g R 16.0 8.8 6:59.12 ora_j021_mydb12 19108 ora 20 0 8856m 310m 275m R 16.0 1.9 0:06.90 ora_j006_mydb12 19191 ora 20 0 8856m 233m 198m R 16.0 1.5 0:04.01 ora_j016_mydb12 19259 ora 20 0 8829m 174m 163m R 15.7 1.1 0:02.84 ora_j008_mydb12 18536 ora 20 0 8857m 516m 481m R 15.4 3.2 0:19.72 ora_j040_mydb12 18939 ora 20 0 8856m 322m 287m R 15.4 2.0 0:07.44 ora_j039_mydb12 |
所以开启concurrent的另外一个建议,就是使用resource manager。
3. 观察concurrent收集的进度:
|
1 2 3 4 5 6 7 8 |
select job_name, state, comments from dba_scheduler_jobs where job_class like 'CONC%'; select state,count(*) from dba_scheduler_jobs where job_class like 'CONC%'; group by state; |
4. 当启用concurrent的时候,同时再使用并行,建议将PARALLEL_ADAPTIVE_MULTI_USER设置成false,关闭并发度的自适应调整。
默认值是true,当使用默认值时,使自适应算法,在查询开始时基于系统负载来自动减少被要求的并行度。实际的并行度基于默认、来自表或hints的并行度,然后除以一个缩减因数。该算法假设系统已经在单用户环境下进行了最优调整。
5. EBS系统应用是采用自己的并发管理器(FND_STATS)来收集统计信息,而收集统计信息用户往往是没有显式授权CREATE JOB、MANAGE SCHEDULER、MANAGE ANY QUEUE的。且EBS中用户众多,不可能为这些应用用户都显式授权。
所以在EBS中不能开启concurrent参数。EBS的安装文档中(Doc ID 396009.1),也是说将数据上收集统计信息的功能关闭的(_optimizer_autostats_job=false)
参考:
https://blogs.oracle.com/optimizer/entry/gathering_optimizer_statistics_is_one
http://blog.csdn.net/lukeUnique/article/details/51705922
Doc ID 1555451.1 – FAQ: Gathering Concurrent Statistics Using DBMS_STATS Frequently Asked Questions
Doc ID 396009.1 – Database Initialization Parameters for Oracle E-Business Suite Release 12