(一)先说明一下定义:
1. 读现象(Read phenomena):
SQL 92标准规定了3种不同的读现象。脏读、不可重复读和幻读。分别解释一下。
1.1 脏读:
A dirty read (aka uncommitted dependency) occurs when a transaction is allowed to read data from a row that has been modified by another running transaction and not yet committed.
也就是说,脏读发生在当一个事务,允许从一行中读取数据,而这行的数据,是在另外一个事务中被修改,且还没有被commit的数据。

此时transaction 1可以看的transaction 2修改过且没有提交的数据,这时就是脏读。
1.2 不可重复读:
A non-repeatable read occurs, when during the course of a transaction, a row is retrieved twice and the values within the row differ between reads.
也就是说,在一个事务中,当两次读取一行的值的时候,得到的值是不同的。这一行被另外一个事务修改且commit了。

在lock-based的并发控制模式下,当执行SELECT时未获取read lock时,或者在执行SELECT操作时释放对应hang上的read lock时,可能会发生不可重复读。或者是在mvcc的并发冲突控制模式下,当受到提交冲突影响的事务必须回滚的要求被放宽时,也可能会发生不可重复读。
1.3 幻读:
A phantom read occurs when, in the course of a transaction, new rows are added or removed by another transaction to the records being read.
也就是说,在一个事务中,你查询的数据,得到的结果,在另外一个事务中被插入或者删除了,并且提交了,而你是可以看的这个变化的。
这里有几个要点:
脏读是还没提交就被读到了;
不可重复读和幻读都是提交之后被读到了;区别是,不可重复读是当前事务是等值查询,而另一事务对该值进行了更新操作;幻读是当前事务是范围查询,而另一事务对该范围进行了插入或删除操作。
解决不可重复读的2个方式,lock-based下加锁并且串行化,事务二必须等待事务一提交,或者mvcc下读snapshot。
解决幻读的方式,也有2个方式,一个是串行化,二是对范围加锁,防止数据插入或者删除。注意在REPEATABLE READ模式(RR模式)下,这个范围其实是没有加锁的,但是mysql的RR模式下引入了gap锁,就解决了这个问题。
解决不可重复的方法,比如锁定等值查询的行,但是还是无法避免幻读的。因为幻读在没有范围锁的情况下,可以插入记录。
2. 事务隔离级别(ANSI/ISO SQL):
ANSI/ISO SQL标准,也定义4个事务隔离级别:
2.1 串行(Serializable,SE):
要求事务是串行的,后一个事务必须等待前一个事务完成才能进行。
整个事务操作过程中,都加锁。
2.2 可重复读(Repeatable reads,RR):
要求在一个事务中,第一次读到的内容,和第二次读到的内容一致。
事务在进行过程中,持续持有读锁和写锁,直到事务完成。同时,没有范围锁,所以该事务隔离级别下还是会出现幻读。但是mysql引入了gap锁,所以mysql在RR隔离级别下,没有幻读。
2.3 提交读(Read committed,RC)
在一个事务中,前一次读到的记录和后一次读到的记录,不一定一致。
事务在进行过程总,持有写锁,读锁不长期持有,读锁只是在读的过程中持有,读完之后就释放了。同时,也没有范围锁。
2.4 未提交读(Read uncommitted,RU)
可以读到未提交的记录。也就是可以读到脏数据。
因此,我们可以画出4种事务隔离级别和3种读现象的兼容图:

(二)好了,讲完了标准的ANSI/ISO SQL定义下的事务隔离级别,我们再来讲讲mysql的事务隔离级别和锁。
3. 事务隔离级别(MySQL):
mysql参考ANSI/ISO SQL,也将自身的隔离级别分成了4种:
3.1 可重复读(RR):
这是mysql的默认事务隔离级别,在这个隔离级别下,你在一个事务内读到的数据,总是一致的。这叫一致性读。
一致性读分为一致性非锁定读和一致性锁定读。
一致性读因为你在第一次读的时候,就生成了对应的视图快照。通常的select语句,就是这种方式。这种一致性读没有锁,因此叫做一致性非锁定读。
对应于一致性非锁定读,那么就是一致性锁定读了。这里就引入了锁的概念(锁lock的概念,后续再介绍)。这常常发生在select for update,delete、update、insert时。
在一致性锁定读的情况下,如果where条件是unique index走unique search,那么此时就只锁定对应索引的行;如果where条件是范围检索,那么此时就会有gap lock和next-key lock。(lock的相关概念,后续再介绍)。
3.2 提交读(RC):
每个事务的一致性读,都会创建自己的视图快照。
对于select for update,update,delete语句,一致性锁定读,只锁定索引行,并不会锁定范围,(范围锁定的gap锁只是在检查外键冲突,或者duplicate key的时候,才会引入。此时类似oracle的mode=4的TX锁)。默认情况下,RC级别是没有gap锁的。
由于RC没有gap锁,所以RC必然有幻读。
另外需要注意的是,主从同步,如果是RC的隔离级别,必须使用row-based binlog(即BINLOG_FORMAT = ROW,如果用MIXED,则server自动改成ROW ),不能使用statement base的binlog(原因:binlog的记录顺序是按照事务commit顺序为序。先提交的先记录在binlog,参考《STATEMENT格式的binlog为何不支持Read-Committed和Read-Uncommitted隔离级别》)。
对于RC,有2个额外的效果需要注意:
注,gap lock在RR下存在,可以通过innodb_locks_unsafe_for_binlog =1(默认为0,参数已过期,在将来版本会取消)来取消gap lock。
但是,即使是设置了innodb_locks_unsafe_for_binlog =1,在RC级别下的外键检查冲突或者duplicated key检测的时候,还是会引入gap lock。
innodb_locks_unsafe_for_binlog=1可以约等于设置事务隔离级别为RC,但是设置事务隔离级别,可以session级设置,另外修改innodb_locks_unsafe_for_binlog 需要重启数据库。
3.3 不提交读(RU):
此隔离级别,读没有锁。所以该事务隔离级别下,不存在读一致性。
3.4 串行(SE):
当autocommit禁用时,innnodb隐式的将select改写是select for share。
当autocommit启用时(默认值),select语句有它自己的事务。
4. MySQL的锁的类型:
MySQL的官方文档中,将MySQL的锁分成了8种类型:
4.1 共享锁和排他锁(Shared and Exclusive Locks)。
innodb的共享锁和排他锁,是一种行锁,类型有两种:
4.2 意向锁(Intention Locks)
innodb的意向锁,是一种表锁,类型有两种:
innodb支持多粒度锁,也就是说,可以在一个行上有S锁或者X锁,在表上可以持有意向锁IS或IX。
当事务T1,持有了表上某个行r的S锁,那么此时另外的一个事务T2,是可以申请S锁在该行r上。在行r上可以同时有T1的S锁和T2的S锁。但是如果事务T2想修改行记录,申请r行的X锁,那么此时需要等待T1释放X锁才可以。
当事务T1,持有了表上某个行r的X锁,那么此时另外一个事务T2,申请该行r上的S锁或者X锁,都会等待。需要等待T1的X锁释放。
意向锁协议遵循如下规则:
在一个事务在表的行上申请S锁之前,它必须在表上获得IS锁或者IX锁。
在一个事务在表的行上申请X锁之前,它必须在表上获得IX锁。
结合上面的T1和T2。
当事务T1,持有了表上的行r的S锁的时候,其实它也是持有表的IS锁。此时,如果事务T2也想申请表上行r的S锁,那么它先要获得表的IS锁,而事务T1的IS锁是兼容事务T2的IS锁,所以不必等待,T2直接获得表的IS锁,然后获得行r的S锁。
当事务T1,持有了表上的行r的S锁的时候,其实它也是持有表的IS锁。此时,如果事务T2想修改记录,申请表上行r的X锁,那么它先要获得表的IX锁,而事务T1的IS锁兼容事务T2的IX锁,所以T2可以先获得表的IX锁,然后T2再申请表的X锁,但是X锁和S锁不兼容,所以需要等T1释放行r的S锁。
当事务T1,持有了表上的行r的X锁的时候,其实它也是持有表的IX锁。此时,如果事务T2想读取记录,申请表上行r的S锁,那么它先要获得表的IS锁,而事务T1的IX锁兼容事务T2的IS锁,所以不必等待,T2直接获得表的IS锁,然后申请行r的S锁,和T1的X锁不兼容,需要等T1释放行r的X锁。(但是我们在实际执行的时候,T2不是用lock base机制,用的是mvcc机制,所以T2是可以看到记录r的snapshot的,不需要等待。)
当事务T1,持有了表上的行r的X锁的时候,其实它也是持有表的IX锁。此时,如果事务T2想修改记录,申请表上行r的X锁,那么它先要获得表的IX锁,而事务T1的IX锁兼容事务T2的IX锁,所以T2可以先获得表的IX锁,然后申请行r的X锁的时候,和T1的X锁不兼容,需要等T1释放行r的X锁。
锁的兼容性表格如下:
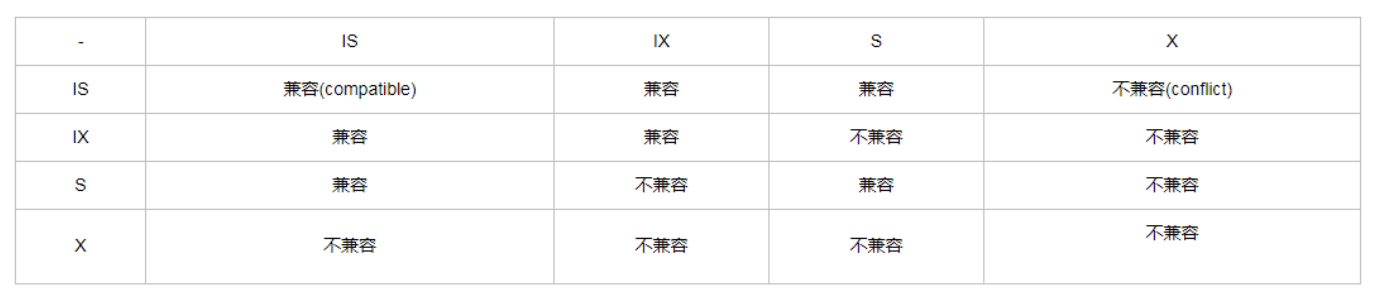
可以看出:
排它锁(X):与任何锁都不兼容
共享锁(S):只兼容共享锁和意向共享锁
意向锁(IS,IX): 互相兼容,行级别的锁只兼容共享锁
4.3 记录锁(Record Locks):
记录锁,锁定的是索引记录。如果表上没有索引,那么用的是隐藏的聚簇索引。
当一条 SQL 没有走任何索引时,那么将会在每一条聚集索引后面加 X 锁,这个类似于表锁,但原理上和表锁是不同的。
4.4 间隙锁(Gap Locks)
gap锁是为了解决幻读问题而生的,RR隔离级别中,防止insert记录产生幻读,而对记录的gap进行锁定,不让别的事务在间隙插入值。RC级别通常没有gap锁(除了外键检测和duplicate key检测之外)。
update操作不会申请gap锁。
gap锁可以跨越单个索引值,多个索引值,甚至是空值。
在通过唯一索引进行唯一查找时,不会用到gap锁。但是有情况例外,就是唯一索引是多列组合索引。
注意,gap的X锁和另外一个事务在同一个gap上的S锁,是兼容的。多冲突类型gap锁之所以能存在是因为:如果某个记录从索引中删除时,这条记录上的gap锁(多个事务持有的)一定会被合并。
gap锁在InnoDB中是专一功能(purely inhibitive),这意味着它们只能防止其他事务在这个间隙中插入数据,而无法阻止不同的事务在同样的间隙上获取间隙锁。所以就间隙锁来说,S锁和X锁效果一样。
gap锁可以通过设置事务隔离级别为RC来禁用。
4.5 Next-Key锁(Next-Key Locks)
Next-Key锁其实是记录锁+间隙锁。它是发生在查询过程中,锁定索引记录以及该索引记录前面的间隙。另外如果没有主键,则会对辅助索引下一个键值加上gap lock。
有shard或exclusive两种模式。
next-key lock还会加在“supremum pseudo-record”上,什么是supremum pseudo-record呢?它是索引中的伪记录(pseudo-record),代表此索引中可能存在的最大值。也就是会锁上当前索引到最大字到正无穷大。
比如:
select* from mytab where col_a>=10 for update;
那么就锁定了10到正无穷到所有值。 此时如果insert into mytable(col_a) values (11);是insert不进去,需要等待前者到select是否锁才可以。
这里需要注意到有2点:
(1)当查询的索引含有唯一属性时,InnoDB会对Next-Key Lock进行优化,将其降级为Record Lock,即仅锁住索引本身,而不是范围。
(2)当一个session当transaction T1中,在行对查询中无论使用了X或者S对gap锁,那么都将阻止另外一个transaction T2对gap进行insert。
(3)InnoDB存储引擎还会对辅助索引下一个键值加上gap lock。
4.6 插入意向锁(Insert Intention Locks)
插入意向锁是一种特殊对gap锁,它是在多个transaction对同一个gap进行插入的时候,且插入是在gap内的不同地方,那么各个transaction不需要彼此等待对方释放锁。目的是为了提高insert的并发。
通常的说,面对即将到来的并发insert,第一个insert会申请插入意向锁,在之前含有gap锁的事务完成之后,释放了gap锁,此时这个insert语句就持有了gap锁,而这个gap锁是特殊的gap锁,即插入意向锁。是允许同一个gap内,如果值不同是允许并发插入的。
4.7 自增锁(AUTO-INC Locks)
自增锁是一种特殊的表锁,是在事务进行insert带有AUTO_INCREMENT字段时获取的。最简单的一个例子是,一个事务在insert表时,另外一个事务需要等待。
自增锁的行为收到参数innodb_autoinc_lock_mode控制。这里根据insert的数据是否可以推测的,分成以下几类:
4.7.1 “Simple inserts”
这种方式的insert是可以预估多少行数的,它是单行或者多行的INSERT 或 REPLACE 语句(注,不包含嵌套子查询),另外, INSERT … ON DUPLICATE KEY UPDATE也是不包含这种insert类型内的。
4.7.2 “Bulk inserts”
这种方式的insert行数是不可预估的。它通常是INSERT … SELECT, REPLACE … SELECT, 和 LOAD DATA,innodb假定每次处理每行数据,AUTO_INCREMENT都是一个新的值。
4.7.3 Mixed-mode inserts”
是simple-insert,但是部分auto increment值给定或者不给定。如在c1是自增值的情况下,INSERT INTO t1 (c1,c2) VALUES (1,’a’), (NULL,’b’), (5,’c’), (NULL,’d’); 如INSERT … ON DUPLICATE KEY UPDATE,
4.7.4 innodb_autoinc_lock_mode可以有值0,1,2:
参考文章:
wikipedia – Isolation (database systems)
MySQL 8.0 Reference Manual – 15.7.2.1 Transaction Isolation Levels