注,需要注意的是raft是个默认消息可靠,但是不提防消息有害的系统。
(一). 共识机制有2种:
一种是leader-less(对称的),即没有leader,大家都是平等的,客户端可以连接任意的节点。
一种是leader-base(非对称的),即有leader,在任意的某个时间点,只有一个leader,其他的节点接受leader的决定。客户端只和leader 节点发生交互。
raft是属于leader-base的共识机制。注意raft是一种协议,那么它就不是一种公式,而是一种分布式系统达成共识的各种条件的约定。
(二)节点状态:
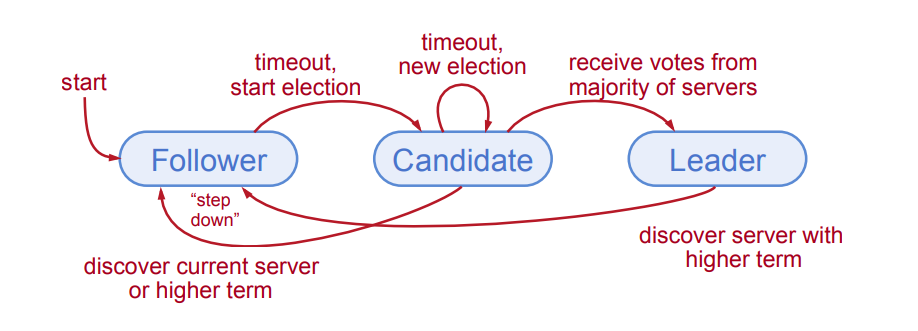
节点的状态有3种,一个是叫follower,一个是candidate,一个是叫leader。各自角色的作用,有如下约定:
(1)leader:会处理来自所有客户端的交互请求,会记录复制的进度,同一时刻,集群中只会有一个leader。
(2)follower:完全被动,不发起RPC请求(Remote Procedure Call,即远程过程调用请求),只是回应RPC请求。
(3)candidate:用于选举leader。
开始的时候,所有节点的状态为follower(后续简称为F),节点在规定的时间内,没有收到来自leader(后续简称为L)的RPC请求,发起投票,先是让自己成为candidate(后续简称C)。
在某一时刻,可能存在多个C,这些C是从F变过来的,从C变成F的时间,各个节点也不尽相同,有些可能久一点,有些可能短一点;各个C也会在不同的瞬间发起投票;而发给F的路径长度不一样,可能收到F的反馈的时间点也不一样。
如果在某个选举的时间单位内,C收到了大部分节点的同意的信息,那么C就变成L,如果没有收到信息,那么发起下来一轮任期的投票。
(三)任期(Term)
raft将时间划分成一个一个的任期。一个是选举期间,一个是常规操作的时间(此时只有一个L)。
有些term是没有L的,
每个节点都保留这当前的任期值。
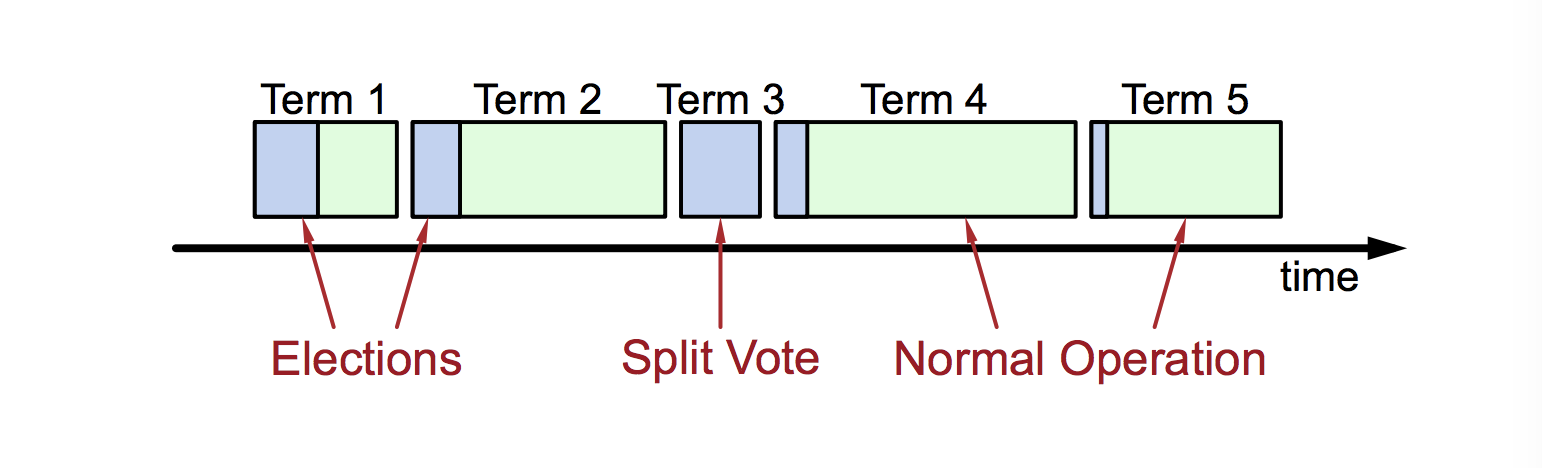
所以,一开始,大家都是F,一开始是出于选举阶段的(蓝色),等选出了L,进入了常规操作时间(绿色),当出现超时或者故障的时候,此时就进入了投票阶段,节点们会发起投票,最后投票结束,又进入了常规操作阶段。
在Term1,需要从F开始选举,所以蓝色部分比较长;在Term2,此时已经有了L,所以只需要确认L和F之间的心跳,所以蓝色比较短;在Term3,L挂掉需要重新投票,新节点获取投票成为L后,进入Term4;Term5和Term2一样。
(四)节点信息持久化
1. 每个节点会以同步的方式,在回应RPC之前,持久化如下信息:

这个可以看出是不是像一个小型的数据库?有日志(记录历史term和command),有数据(current term和votefor)?
2. 不用持久化的信息:

(五)心跳和timeout:
1. RPC请求包括两种类型的RPC请求,一种是AppendEntries,如写日志,如发送心跳,是有L发出来的;一种是VOTE,是由C发出来的。
timeout分成两种,第一种是(待补充,见http://thesecretlivesofdata.com/raft/)
2. 初始状态,大家都是F
3. F期望收到的是来自C或L的RPC请求
4. L必须不停的发送AppendEntries来维持自己的领导地位
5. 如果在选举时间(通常是100-500ms)内,L没有收到RPC请求,那么F就认为L已经死掉,F会开始一个新的选举。
(六)选举:
F选举时,会先设定一个超时的时间,是∆election到2倍的∆election时间之间。
会递增当前的Term的值。
F的状态会变成C。并且投票的第一票是给自己。并且给其他所有的节点发送VOTE的RPC请求。然后:
1. 如果在timeout内收到了大部分节点的回应,则这自己成为L。并且发送AppendEntries 给其他所有节点。
2. 如果别的节点已经成为了L,此时从别的节点收到AppendEntries的请求,则自己降成F。
3. 如果从其他节点没有收到任何消息,timeout,则重新发起选举。
4. 当选举完成之后,如果保证选举正确?
4.1 Safty(允许在一个Term内,最多只有一个L):
(a)每个节点在每次term内,只投出一票。
(b)2个不同的C,不能在同一个的term内累积“大多数”的投票。
4.2 Liveness(一些C必须最终获胜)
(a)election timeouts是随机的,(在∆election到2倍的∆election之间)
(b)在其他节点醒来之前,一个先发起的节点通常会timeout,并且赢得选举。
(c)如果∆election >> broadcast time,这种Liveness的机制将会工作的很好。
(七)日志的结构:
1. log是被持久化在磁盘上,用于crash恢复
2. commited的意思是,被大多数节点已经写入。
3. 最终一致性
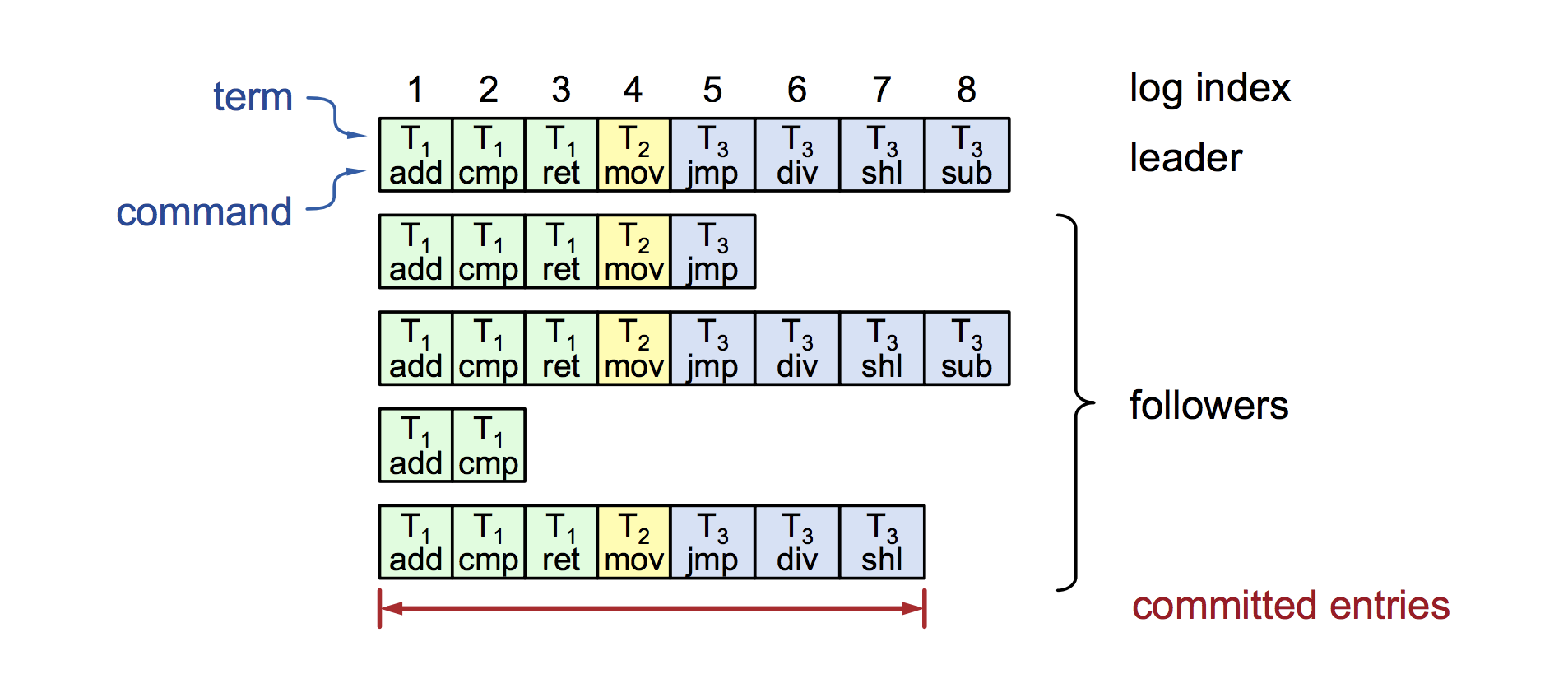
可以从上图看到日志的结构,包含2部分,一部分是term的值,一部分是command的历史信息。
(八)常规操作:
1. 客户端将command传给L
2. L将command写日志
3. L将AppendEntries的RPC请求发给F
4. 一旦新条目commit,L将command传自己的状态机,向客户端返回结果。L在后续AppendEntries的RPC请求中告诉告诉F,被commit的条目。F将commit命令发给自己的状态机。
5. 遇到crash或者slow的客户端,L会一直尝试发送直到成功。通常情况下的性能最佳:一个成功的RPC请求给大多数个节点。
(九)一致性
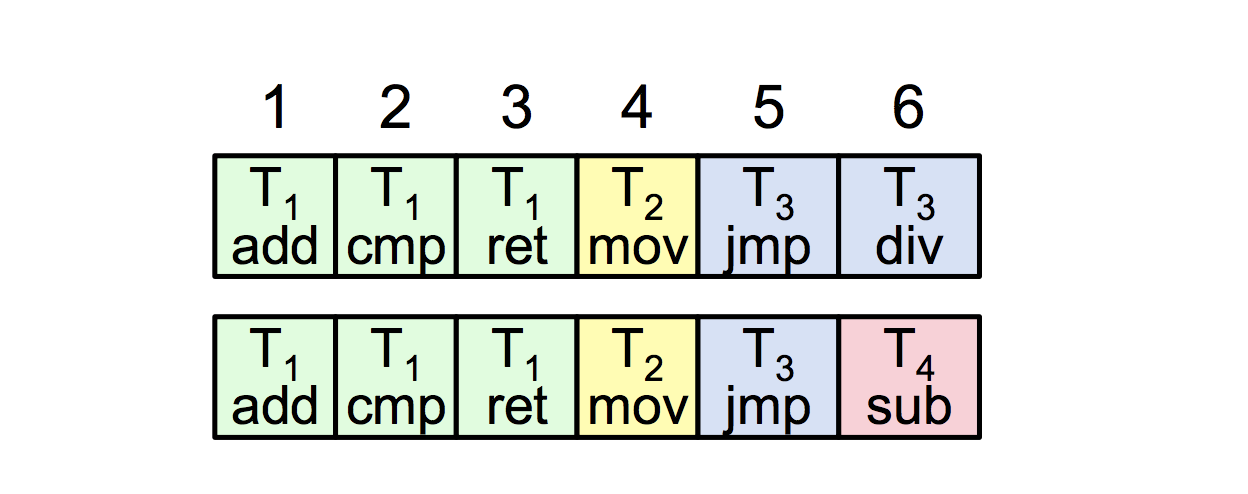
1. 什么是日志的一致性:所有的节点的日志,都有一样的index和term;如果某个给定的条目是已经commit的了,那么前面的所有的条目也是commit的。
如下图所示,数字123456是代表log index,所有的节点,都有一样的index和term,且某个给定的条目,如index=4,T2的条目,已经是commit的,那么之前的条目也都是commit的。
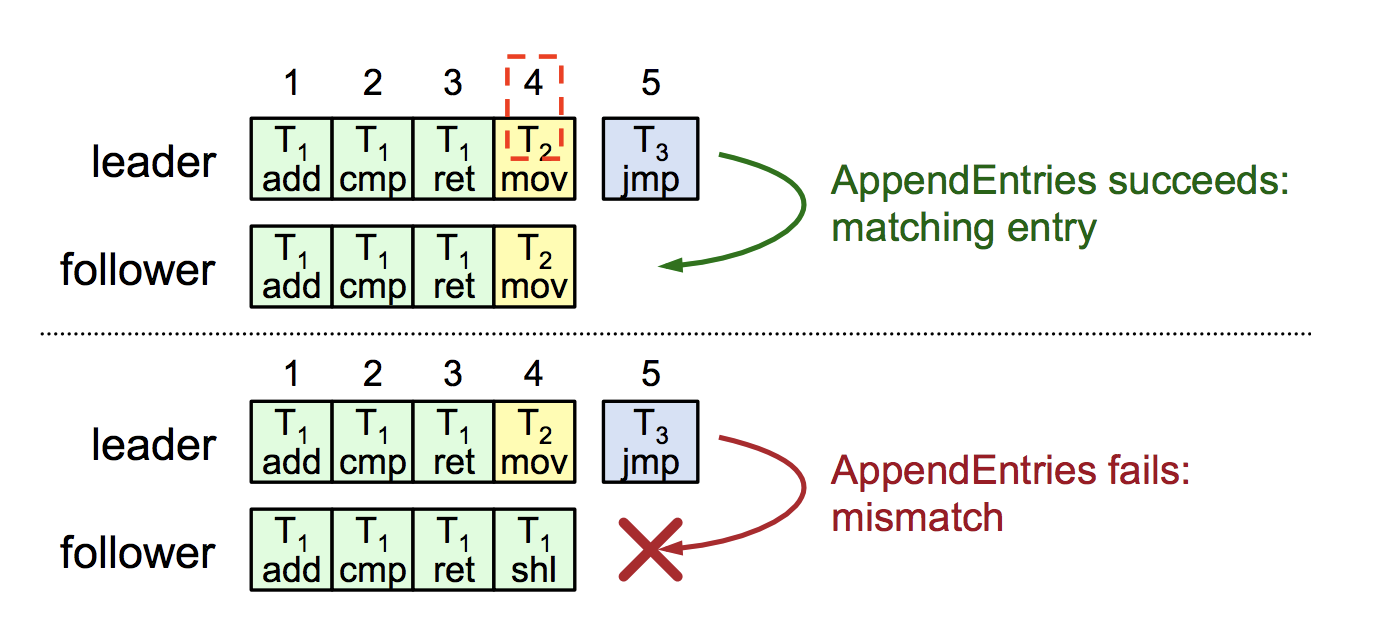
2. 什么是AppendEntries的一致性检查:每个AppendEntries的RPC请求,都包含需要处理的新的index和term;F必须包含有相符合的条目,不然就拒绝新来的AppendEntries请求;将上述步骤实施递归步骤,确保一致性。
如下图所示,每个新来的AppendEntries RPC请求,都包含了index和term,且在下面的第二个图中,由于F包含的条目和L不一致,所以会拒绝log index=5的新的AppendEntries的请求。
(十)Leader的产生
1. L产生的开始:
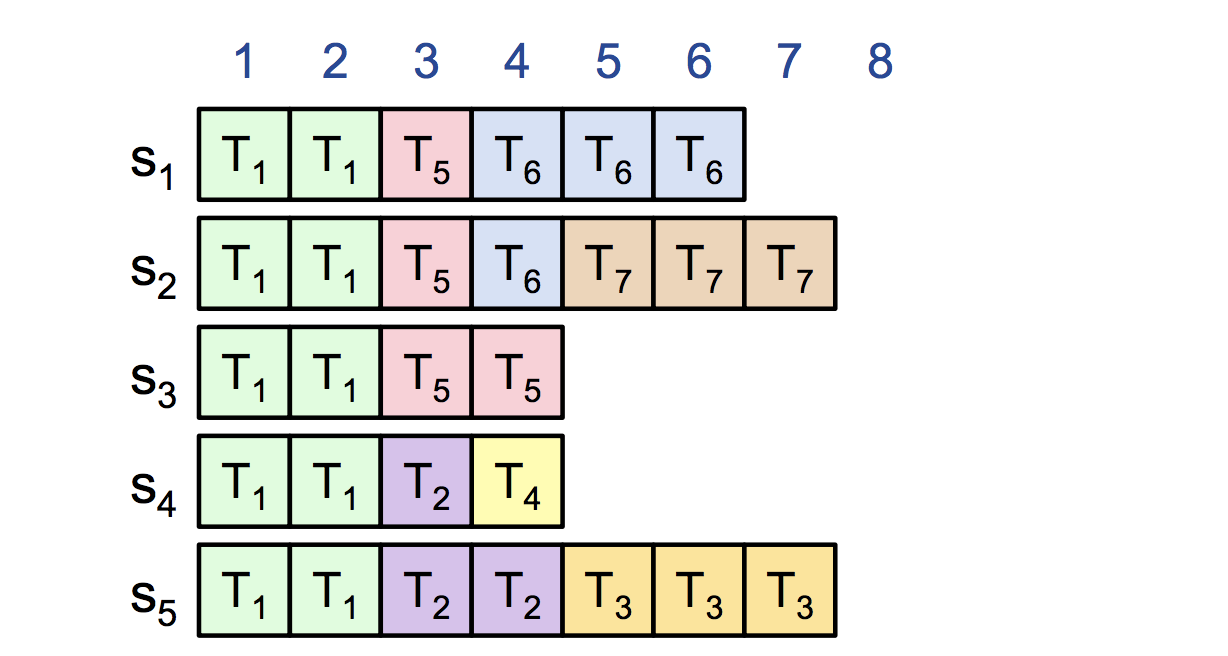
1.1 旧的L可能会留下一下部分被同步的条目
1.2 新的L只是做“常规操作”,并不会做一些特别的动作。
1.3 L的日志,是“真理”,会以L的日志为准。
1.4 F的日志最终会到达和L一致。最终一致性。
1.5 多次崩溃可能会留下许多无关的日志条目。
2. Safty的要求:
2.1. 如果L已确认某个log条目是已经commit了的,则该条目将出现在所有未来L的日志中
2.2. L不会覆盖写日志的条目:只有在L的日志中的条目,才能被commit;日志条目只有commit之后,才会被同步到其他节点。
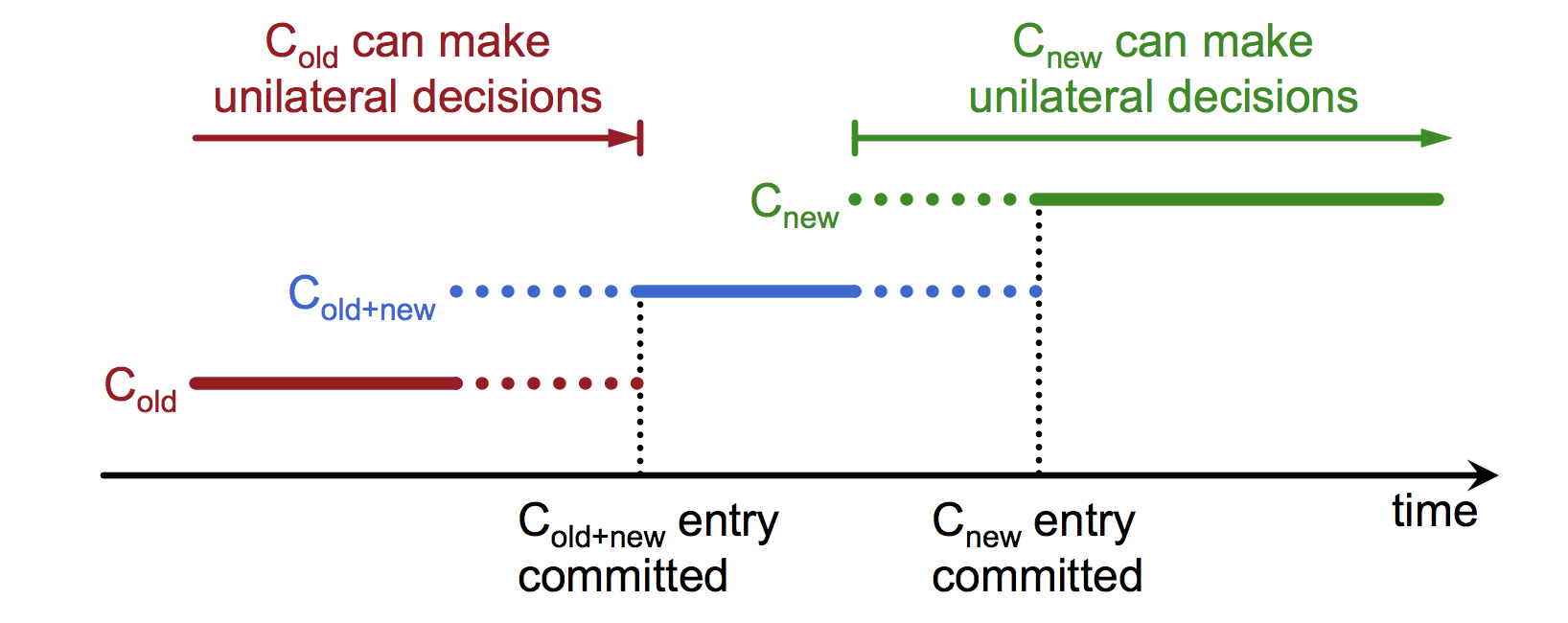
2.3. 集群成员数量改变,每次只变一台,不同时变多台。即使有,在内部操作时也是拆成一台一台的改变。如果同时改变多台,可能出现脑裂的情况,同一时刻有老配资的leader和新配置的leader,两个leader。
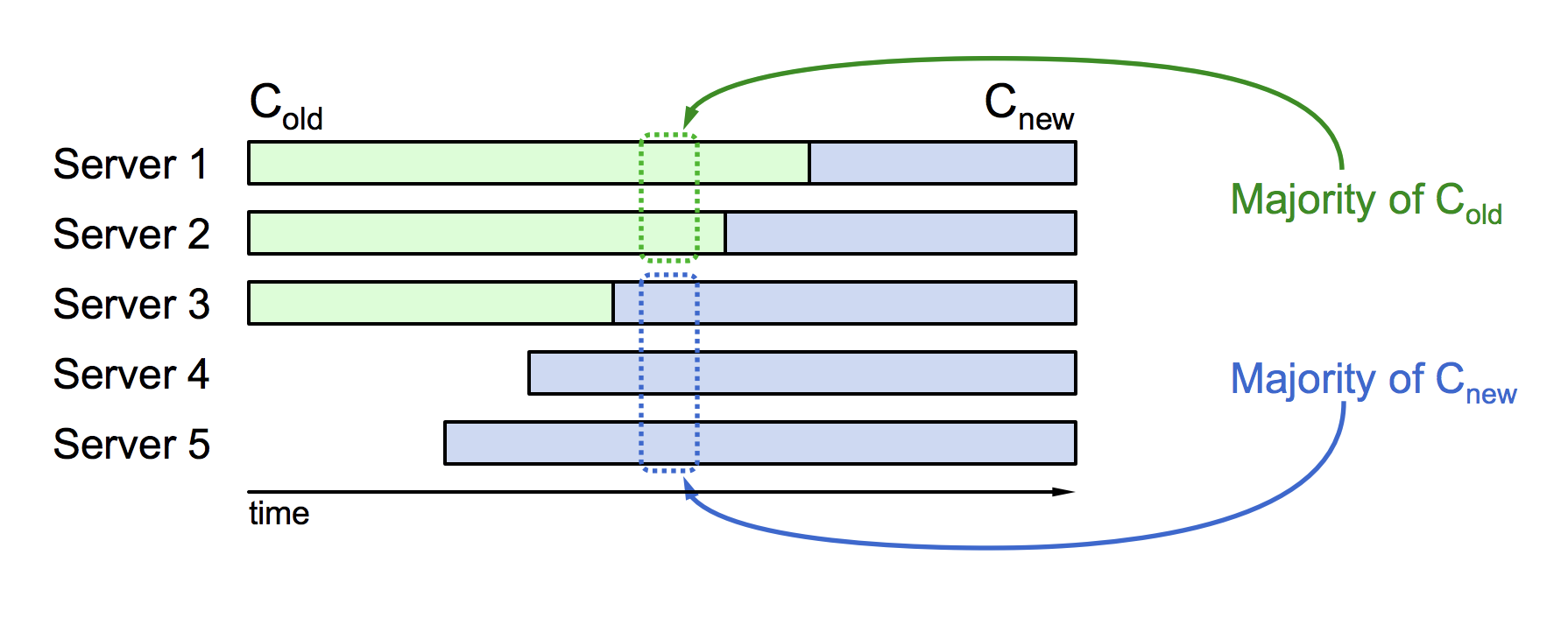
2.4. 集群成员数量改变,采用两阶段方法变动(即存在同时为C-old和C-new,老配置和新配置同时生效的时刻)。