华西某省进行数据库主机升级,将一台老机器升级到新机器上,在新机器上安装完数据库软件之后,把存储从老机器往新机器一挂,数据库算是迁移完成了。但是自从升级完成后,legato一直备份不成功。为了这个问题,和华西的dba王术成研究了好几天。
第一天:
发现备份执行完了,但任务状态不恢复正常,检查数据库主机的归档目录,arch日志已经被备份走,但是在legato的GUI界面,发现还是备份作业未完成的闹钟状态:

重启server端的networker服务,无效。重启client端的networker服务,无效。
检查相关进程:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
root@gz_dc01:/ # ps -ef |grep nsr root 17205 16714 0 12:38:21 ? 0:01 /opt/networker/bin/nsrmmd -n 7 -s gz_bak01 root 17207 16714 0 12:38:24 ? 0:00 /opt/networker/bin/nsrmmd -n 9 -s gz_bak01 root 17584 16714 0 12:43:22 ? 0:00 /opt/networker/bin/nsrmmd -n 2 -s gz_bak01 root 20543 1 0 13:20:12 ? 0:00 /bin/sh /opt/networker/bin/nsrnmo1 -s gz_bak01 -g OracleArch -L root 17204 16714 0 12:38:19 ? 0:00 /opt/networker/bin/nsrmmd -n 5 -s gz_bak01 root 20544 20543 192 13:20:12 ? 47:29 nsrnmostart -s gz_bak01 -g OracleArch -LL -m gz_db -l full -q - root 24951 24484 0 14:17:33 pts/tb 0:00 grep nsr root 16714 16712 0 12:32:08 ? 0:00 /opt/networker/bin/nsrexecd root 16712 1 0 12:32:08 ? 0:00 /opt/networker/bin/nsrexecd root@gz_dc01:/ # root@gz_dc01:/ # |
发现rman进程已经完成,按照原理,当rman备份完的时候,会写index和bootstrap,但是目前却一直停留在rman完成的状态,nsrnmostart -s gz_bak01 -g OracleArch -LL -m gz_db -l full -q -进程一直挂死。如果在GUI界面中stop掉作业,在client端还是能看到上述的进程。
在GUI重新配置group和client,指定scheduel,再次备份,还是挂死,且此次rman备份完之后,磁带都没被eject出来,手工umount磁带,报错了,晕倒!
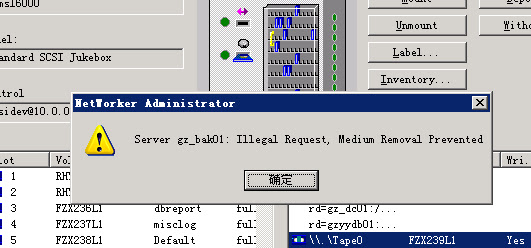
没有其他什么办法了,只好叫人去机房重启带库。
第二天:
昨晚重启带库后,今天尝试备份还是一样的挂死,按理说应该开始备份index和bootstrap了,而index和bootstrap是需要用tape0或者tape1来写,是否是本地驱动器的问题?检查用tape0和tape1做label,发现能正常完成。但是在检查计算机的硬件时,发现介质变换器被启动了!
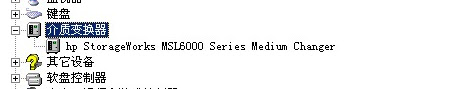
介质变换器是带库在windows机器上的硬件显示,带库是HP的MSL 6000的带库。但是由于我们在windows安装legato的备份软件,legato会调用自己的接口去找带库。如果启动了介质变换器,就容易造成legato自身的接口和介质变换器的接口之间的争用。因此必须禁用介质变换器。
ps:如果是用DP的备份软件,则一定不能禁用介质变换器。DP需要通过介质变换器去调用带库。
禁用后,测试备份,还是挂死。
重启windows机器,重启client的networker的服务,重新配置jbconfig。原以为找到原因了,却还是不行。彻底崩溃……
第三天:
为啥还是不能写index和bootstrap,难道真的是本地驱动器有问题?去HP的网站上下载了LTT(HP StorageWorks Library and Tape Tools),用LTT检查driver状态正常,升级driver和library的firmware:
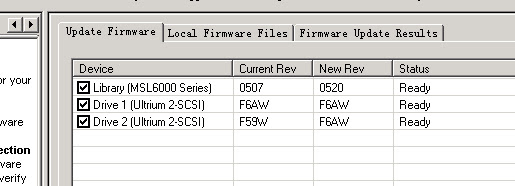
再次尝试备份,还是挂死。
再次核对各个脚本,oraclearch备份脚本,nsrnmo1脚本:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 |
#!/bin/sh # # $Id: nsrnmo.template,v 1.3.52.4 2003/06/25 21:42:19 yozekinc Exp $ Copyright (c) 2003, Legato Systems, Inc. # # All rights reserved. # # nsrnmo.sh # # Legato Networker Module for Oracle 4.1 # # This script is part of the Legato NetWorker Module for Oracle. # Modification of this script should be done with care and only after reading # the administration manual included with this product. # # This script should only be run as part of a scheduled savegroup. # # Returns 0 on success; 1 on failure. # # # REQUIRED Variable: ORACLE_HOME # # Default value: NONE (site specific) # # Description: Specifies where the Oracle Server installation is located. # It is a requirement that rman be located in ORACLE_HOME/bin. # # Samples: # ORACLE_HOME=/disk3/oracle/app/oracle/product/8.1.6 # ORACLE_HOME=/oracle/app/oracle/product/9.2.0 # REQUIRED Variable: PATH # # Default value: NONE (site and platform specific) # # Description: Set up the PATH environment variable. # This must be configured to include the path to "nsrnmostart" # # Samples: # PATH=/bin:/usr/sbin:/usr/bin:/nsr/bin:/opt/networker/bin # PATH=/bin:/usr/sbin:/usr/bin:/nsr/bin:/opt/networker/bin # # Optional Variable: ORACLE_SID # # Default value: NONE (site specific) # # Description: Specifies the SID of the Oracle database being backed up. # It is required by proxy copy backups when catalog synchronization is # enabled. # # Samples: # ORACLE_SID=orcl815 # ORACLE_SID=gzmisc # # Optional Variable: NSR_RMAN_ARGUMENTS # # Default value: NONE (site specific) # # Description: Provide extra rman parameters. # You must enclose the command in quotes or it will not be # passed correctly to rman. # # Samples: # NSR_RMAN_ARGUMENTS="nocatalog msglog '/nsr/applogs/msglog.log' append" # # NSR_RMAN_ARGUMENTS="nocatalog" # NSR_RMAN_ARGUMENTS="msglog '/nsr/applogs/msglog.log' append" # # Optional Variable: NSR_RMAN_OUTPUT # # Default value: NONE (site specific) # # Description: Provide option to capture the RMAN standard output # if RMAN "msglog" or "log" command line option is not set. # The connect strings will be hidden in this file. # # Samples: # NSR_RMAN_OUTPUT="/nsr/applogs/msglog.log append" # # NSR_RMAN_OUTPUT="/nsr/applogs/msglog.log" # NSR_RMAN_OUTPUT="/nsr/applogs/msglog.log append" # # Optional Variable: NSR_SB_DEBUG_FILE # # Default value: NONE (site specific) # # Description: To enable debugging output for NMO scheduled backups set # the following to an appropriate path and file name. # Set this variable for debugging purposes only # # Samples: # NSR_SB_DEBUG_FILE=/nsr/applogs/nsrnmostart.log # NSR_SB_DEBUG_FILE= # # Optional Variable: PRECMD # # Default value: NONE # # Description: This variable can be used to run a command or command script # before nsrnmostart. It will be launched once for every saveset # entered in the client setup. # PRECMD= # # Optional Variable: POSTCMD # # Default value: NONE # # Description: This variable can be used to run a command or command script # after nsrnmostart has completed. It will be launched once for # every saveset entered in the client setup. # POSTCMD= # # Optional Variable: SHLIB_PATH,LD_LIBRARY_PATH # # Default value: NONE # # Description: These variables may have to be set on HP-UX 11.0 (64 bit) operating systems. # We suggest leaving it unset unless you have a scheduled backup problem. # If it is set you must also uncomment the export SHLIB_PATH and LD_LIBRARY_PATH # in the function export_environment_variables below. # # Samples: # SHLIB_PATH=/disk3/oracle/app/oracle/product/8.1.6/lib # LD_LIBRARY_PATH=/disk3/oracle/app/oracle/product/8.1.6/lib64 # # # Optional Variable: TNS_ADMIN # # Default value: NONE # # Description: This variable needs to be set if Oracle Net configuration # files are not located in default locations.If it is set you must also uncomment # the export TNS_ADMIN in the function export_environment_variables below. # # Samples: # TNS_ADMIN=/disk3/oracle/app/oracle/product/8.1.6/network/admin1 # export_environment_variables() { export ORACLE_HOME export ORACLE_SID export NSR_RMAN_ARGUMENTS export NSR_RMAN_OUTPUT export PRECMD export POSTCMD export PATH export NSR_SB_DEBUG_FILE #export SHLIB_PATH #export LD_LIBRARY_PATH #export TNS_ADMIN } ########################################################################### # Do not edit anything below this line. ########################################################################### Pid=0 # process to kill if we are cancelled nsrnmostart_status=0 # did it work? # # Handle cancel signals sent by savegrp when user stops the group. # handle_signal() { if [ $Pid != 0 ]; then kill -2 $Pid fi exit 1 } # # The main portion of this shell. # # # Make sure we respond to savegrp cancellations. # trap handle_signal 2 15 # # Build the nsrnmostart command # opts="" while [ $# -gt 0 ]; do case "$1" in -s ) # server name opts="$opts $1 '$2'" shift 2 ;; -N ) # save set name opts="$opts $1 '$2'" shift 2 ;; -e ) # expiration time opts="$opts $1 '$2'" shift 2 ;; -b ) # Specify pool opts="$opts $1 '$2'" shift 2 ;; -c ) # Specify the client name opts="$opts $1 '$2'" shift 2 ;; -g ) # Specify group opts="$opts $1 '$2'" shift 2 ;; -m ) # Specify masquerade opts="$opts $1 '$2'" shift 2 ;; -A ) # Specify PowerSnap options opts="$opts $1 '$2'" shift 2 ;; *) # rest of options opts="$opts $1" shift ;; esac done if [ "${BACKUP_OPT}" != "" ]; then BACKUP_COMMAND_LINE="nsrnmostart ""$BACKUP_OPT"" $opts" else BACKUP_COMMAND_LINE="nsrnmostart $opts" fi # # Export all necessary environment variables # export_environment_variables # # Call nsrnmostart to do the backups. # #print $BACKUP_COMMAND_LINE eval ${BACKUP_COMMAND_LINE} & Pid=$! wait $Pid nsrnmostart_status=$? if [ $nsrnmostart_status != 0 ] ; then echo "nsrnmostart returned status of "$nsrnmostart_status echo $0 "exiting." exit 1 fi exit 0 |
发现均正常。
通过检查脚本,添加log跟踪调试,也了解了legato的调用原理,在windows的机器上调用client的nsrnmo1脚本,nsrnmo1脚本会接收从windows主机传来的参数,再调用nsrnmostart脚本,生成执行语句。因此上面的脚本中的第254行,我们跟踪到实际的语句是:
|
1 |
nsrnmostart -s 'gz_bak01' -g 'OracleArch' -LL -m 'gz_db' -t 1235638289 -l incr -q -W 78 -N '/oracle/app/oracle/product/9.2.0/bin/oraclearch' /oracle/app/oracle/product/9.2.0/bin/oraclearch |
当nsrnmo1执行完成后,再写index和bootstrap。此时一个想法升起:难道是nsrnmo1无法正常结束才导致后续写index和bootstrap无法进行?
尝试在GUI中再次启动备份作业,但是挂死的时候,kill掉nsrnmo1的进程,果然!开始写index和bootstrap了!
但是,为何nsrnmo1无法正常结束呢?
第四天:
在网上搜索相关的信息,发现一个CU的帖子是和我遇到问题的现象很类似。原因是nsrnmo的版本问题,他在oracle 10g下,用nmo 4.2不能正常结束进程,但是用nmo 4.1却可以正常结束。赶紧叫主机工程师查nmo版本,结果是令人兴奋的!!:
发生问题的贵州的nmo版本是:
NMO 4.2 NetWorker Module for Oracle
NetWorker 7.1.2.Build.325 NetWorker for HP-UX 11.XX (64-bit)
对比能正常备份的陕西的版本是:
NMO 4.1 Legato NetWorker Module for Oracle
NetWorker 7.1.2.Build.325 NetWorker for HP-UX 11.XX (64-bit)
再次问了做工程的工程师,他说当时在桌上拿了张光盘,也没仔细看版本!!
于是赶紧重新安装了nmo4.1的包,再次测试备份,终于这次备份终于在rman备份结束后,开始抓带写index和bootstrap了!不过兴奋的心情很快就消失了,在抓带的时候,又报错read open error:

第五天:
如果备份的时候,报错read open error,那么我测试label会怎么样呢?
用slow方式指定tape0或者tape1做label,正常。
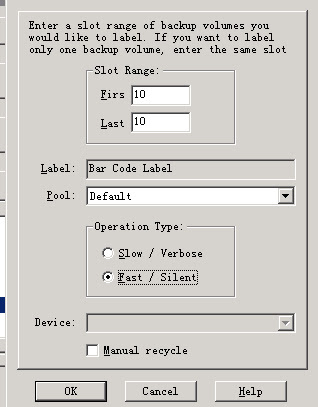
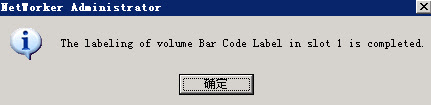
用fast的方式,报错:
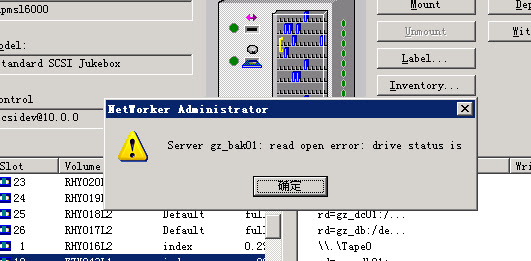
再次尝试备份,log中还是一样的报错:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
02/20/09 11:04:06 nsrd: media event cleared: Waiting for 1 writable volumes to backup pool 'Default' tape(s) on gz_dc01 02/20/09 11:04:06 nsrd: gz_db:/oracle/app/oracle/product/9.2.0/bin/oraclearch saving to pool 'Default' (FZX239L1) 02/20/09 11:04:06 nsrd: gz_db:/oracle/app/oracle/product/9.2.0/bin/oraclearch saving to pool 'Default' (FZX239L1) 02/20/09 11:04:25 nsrd: gz_db:/oracle/app/oracle/product/9.2.0/bin/oraclearch done saving to pool 'Default' (FZX239L1) 255 MB 02/20/09 11:04:28 nsrd: gz_db:/oracle/app/oracle/product/9.2.0/bin/oraclearch done saving to pool 'Default' (FZX239L1) 522 MB 02/20/09 11:04:42 nsrd: media info: suggest mounting FZX243L1 on gz_bak01 for writing to pool 'index' 02/20/09 11:04:42 nsrd: media waiting event: Waiting for 1 writable volumes to backup pool 'index' tape(s) on gz_bak01 02/20/09 11:04:43 nsrd: media info: loading volume FZX243L1 into \\.\Tape1 02/20/09 11:04:44 nsrmmd #12: Start nsrmmd #12, with PID 544, at HOST gz_bak01 02/20/09 11:05:01 nsrd: \\.\Tape1 1:Verify label operation in progress 02/20/09 11:05:04 nsrd: write completion notice: Writing to volume FZX239L1 complete 02/20/09 11:05:16 nsrd: media warning: \\.\Tape1 reading: read open error: drive status is The tape drive is ready for use 02/20/09 11:05:17 nsrd: \\.\Tape1 1:Eject operation in progress 02/20/09 11:05:57 nsrd: Jukebox 'hpmsl6000' failed: expected volume 'FZX243L1' got 'NULL'. 02/20/09 11:06:04 nsrd: media info: suggest mounting RHY016L2 on gz_bak01 for writing to pool 'index' 02/20/09 11:06:05 nsrd: media info: loading volume RHY016L2 into \\.\Tape1 02/20/09 11:06:22 nsrd: \\.\Tape1 1:Verify label operation in progress 02/20/09 11:06:38 nsrd: media warning: \\.\Tape1 reading: read open error: drive status is The tape drive is ready for use 02/20/09 11:06:38 nsrd: \\.\Tape1 1:Eject operation in progress 02/20/09 11:07:18 nsrd: Jukebox 'hpmsl6000' failed: expected volume 'RHY016L2' got 'NULL'. 02/20/09 11:07:24 nsrd: media info: Suggest manually labeling a new writable volume for pool 'index' |
按照log的建议,手工label一卷磁带到index pool,仍然报错read open error。
找来北办的dba,Rill来一起讨论这个问题,他说之前遇到过类似的问题,可以试试将device的CDI的访问方式从scsi command该成not used:
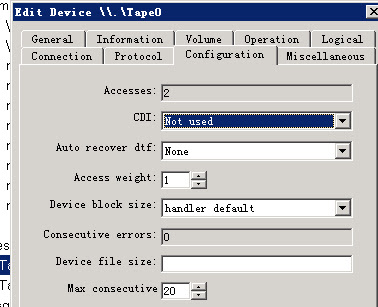
修改之后,再次备份,哇!终于成功了!
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
02/20/09 13:06:18 nsrd: media info: suggest mounting FZX243L1 on gz_bak01 for writing to pool 'index' 02/20/09 13:06:18 nsrd: media waiting event: Waiting for 1 writable volumes to backup pool 'index' tape(s) on gz_bak01 02/20/09 13:06:19 nsrd: media info: loading volume FZX243L1 into \\.\Tape1 02/20/09 13:06:20 nsrmmd #12: Start nsrmmd #12, with PID 5680, at HOST gz_bak01 02/20/09 13:06:37 nsrd: \\.\Tape1 2:Verify label operation in progress 02/20/09 13:06:41 nsrd: write completion notice: Writing to volume FZX239L1 complete 02/20/09 13:07:01 nsrd: \\.\Tape1 2:Mount operation in progress 02/20/09 13:07:07 nsrd: media event cleared: Waiting for 1 writable volumes to backup pool 'index' tape(s) on gz_bak01 02/20/09 13:07:07 nsrd: gz_bak01:index:gz_db saving to pool 'index' (FZX243L1) 02/20/09 13:07:12 nsrd: gz_bak01:index:gz_db done saving to pool 'index' (FZX243L1) 22 KB 02/20/09 13:07:16 nsrd: gz_bak01:bootstrap saving to pool 'index' (FZX243L1) 02/20/09 13:07:17 nsrmmdbd: media db is saving its data. This may take a while. 02/20/09 13:07:17 nsrmmdbd: media db is open for business. 02/20/09 13:07:19 nsrd: gz_bak01:bootstrap done saving to pool 'index' (FZX243L1) 802 KB 02/20/09 13:07:25 nsrd: savegroup info: Added 'gz_bak01' to the group 'OracleArch' for bootstrap backup. 02/20/09 13:07:25 nsrd: savegroup notice: OracleArch completed, total 2 client(s), 0 Hostname(s) Unresolved, 0 Failed, 2 Succeeded. 02/20/09 13:08:07 nsrd: write completion notice: Writing to volume FZX243L1 complete |
可是为啥割接之前配置的scsi commands是能够备份的,现在却不可以了呢?
再次把CDI的参数改回scsi commands,见鬼了!这次,能正常备份了!
第六天:
继续追究这个问题,通过查阅相关文档发现:在CDI手工改成not use的时候,会自动清洗一下磁带,而我们之前总是报错read open error,应该就是driver需要清洗了。当CDI改成not used之后,就被清洗了一次,当再次改回scsi commands的时候,由于磁带被清洗过,于是也就正常备份了。
附文档《Legato Command Reference》中的描述:
Next, if the jukebox contains tape devices, you are asked if automated cleaning of devices in the
jukebox should be turned on. If automated cleaning is enabled, the jukebox and all devices in the
jukebox are configured for automated cleaning. On successful installation, the information that
pertains to device cleaning for the jukebox and all its devices are displayed. Note that with the
introduction of the Common Device Interface (CDI), NetWorker now has two events that will
cause an automatic cleaning to occur: schedule-based cleaning, with devices being cleaned after a
certain (configurable) amount of time has elapsed, and on-demand cleaning, where cleaning is initiated
by TapeAlert warnings issued by the devices. Schedule-based cleaning is always active when
autocleaning is enabled. On-demand cleaning is used when the CDI attribute for a tape device is
set to anything other than ’Not Used’ in the device resource. If on-demand cleaning is being used,
you should set the Cleaning Interval for the device itself to a large time, such as 6 months, so that
NetWorker does not clean the device unnecessarily. See nsr_device.5 for a more detailed explanation
of CDI, TapeAlert and Cleaning Interval.
至此,问题和疑惑终于全部解决!
6条评论
很值得学习,
顺便问一下,你的网站怎么注册啊。
re jason:我是在dreamhost注册的。注册之后有一键install,完成的很快的。之后把mysql的连接串配一下,就完成了。
jm,我是广西的hfg,无意中看到你的这个帖子。关于The tape drive is ready for use的问题,我也是折腾了很久,得到的结结论和你的差不多,不知道是你早还是我早,如果能早点共享就好了:)但是根据我收集到的资料,似乎没有提到从CDI转到not use的时候会清洗磁带,我理解只是对磁带机控制方式的不同。以下是我收集到的一些信息,共享吧:
———————————————————————————
The CDI feature controls how tape drive cleaning is handled.
———————————————————————————
CDI was introduced in NetWorker 7 and is a new API used for communicating with tape devices. CDI helps because it have (sometimes) better clearer error messges and it uses Tape Alert. There have been lots of problems with CDI and certain tape drives.
The best way then usually is to turn off CDI and use the old way off communcating with the tape drive. This is a attribute on the tape device resource in NetWorker you can change from “SCSI commands” to “Not used”.
CDI is a good thing when it is working so you should only change it for test purposes and see if it makes any difference for you. However, I have never had problems with LTO and CDI so far.
———————————————————————————
CDI (read-write, no create)
Not used essentially turns off the use of CDI.
SCSI commands
NetWorker will use the CDI interface to send explicit
SCSI commands to tape drives. This allows the best
control of and status collection from a device and is
the default for SCSI or SCSI-like tape drives directly
under NetWorker’s control.
刚看到这段“【文章发布信息】发表于: 2009-02-26 @ 19:38:46 ”,我大概是08年12月初发现的这个情况,可能我发现得稍早一点。如果信息沟通能充份一点,你就可以少这段折腾了,呵呵。
re wind_7th:呵呵,是啊,公司就是缺这样的一个交流平台。郁闷!
这个我也用过,给折磨坏了,只是用在了 sybase上