2023年11月27日,aws 宣布了他们的新的产品,aws无限数据库(limitless database)。我比较关注这个新产品,简单谈谈对他的看法。
大部分的信息,是来自于《AWS re:Invent 2023 – Monday Night Live Keynote with Peter DeSantis》 这场演讲。这场演讲还是非常有逻辑性的,整个故事,还是得从serverless谈起……
1. aws一直在追求serverless。数据库也在向这个方向努力。
2. aws发布了aurora rds,兼容pg和mysql,aurora最大的创新,是优化的分布式存储系统,内部代号叫grover。通过grover,实现了算存分离,实现了The log is database。grover能显著减少IO消耗,实现用多少算多少,能简单快速的复制节点,为serverless打下了基础。
3. 但是grover实现的,并不是真正的serverless,比如它只是能增加只读副本,不能增加读写节点。如果要扩展读写节点,你还是需要扩容升级,需要做failover迁移。
4. 所以aws推出了aurora serverless服务。做到了无需调整数据库大小,进行failover迁移。在serverless中,数据库可以根据自己使用的情况,来申请内存。但是传统的方式中,数据库的内存是基于宿主机的内存大小,如果要申请更多的内存,那么就要关闭宿主机,分配更大内存,期待宿主机,启动更大内存的数据库—— 这就是Nitro虚拟化做的事情,但是Nitro这么做不是serverless,因为这会导致数据库重启。所以aws引入了一个新的功能,名为Caspian。它是一个融合虚拟化管理系统、热管理计划系统,并且对数据库引擎本身有做一些改动。Caspian使用一种叫做“合作-超额认购”的方法,可以为每个启动的数据库的宿主机,都分配物理机所有的内存一样的大小,但是实际使用,只是数据库所申请的内存大小。当物理机上的多个数据库已经使用了所有物理内存并且需要申请更多的时候,Caspian会把其中一个实例迁移到另外的物理机,再给申请的数据库扩容内存。
5. Caspian解决了所有问题吗? 并没有。如果一个数据库申请的内存,超过了一个物理机所拥有的内存,该怎么办? 这个时候,就要采用分片技术了,这就是aurora limitless database。
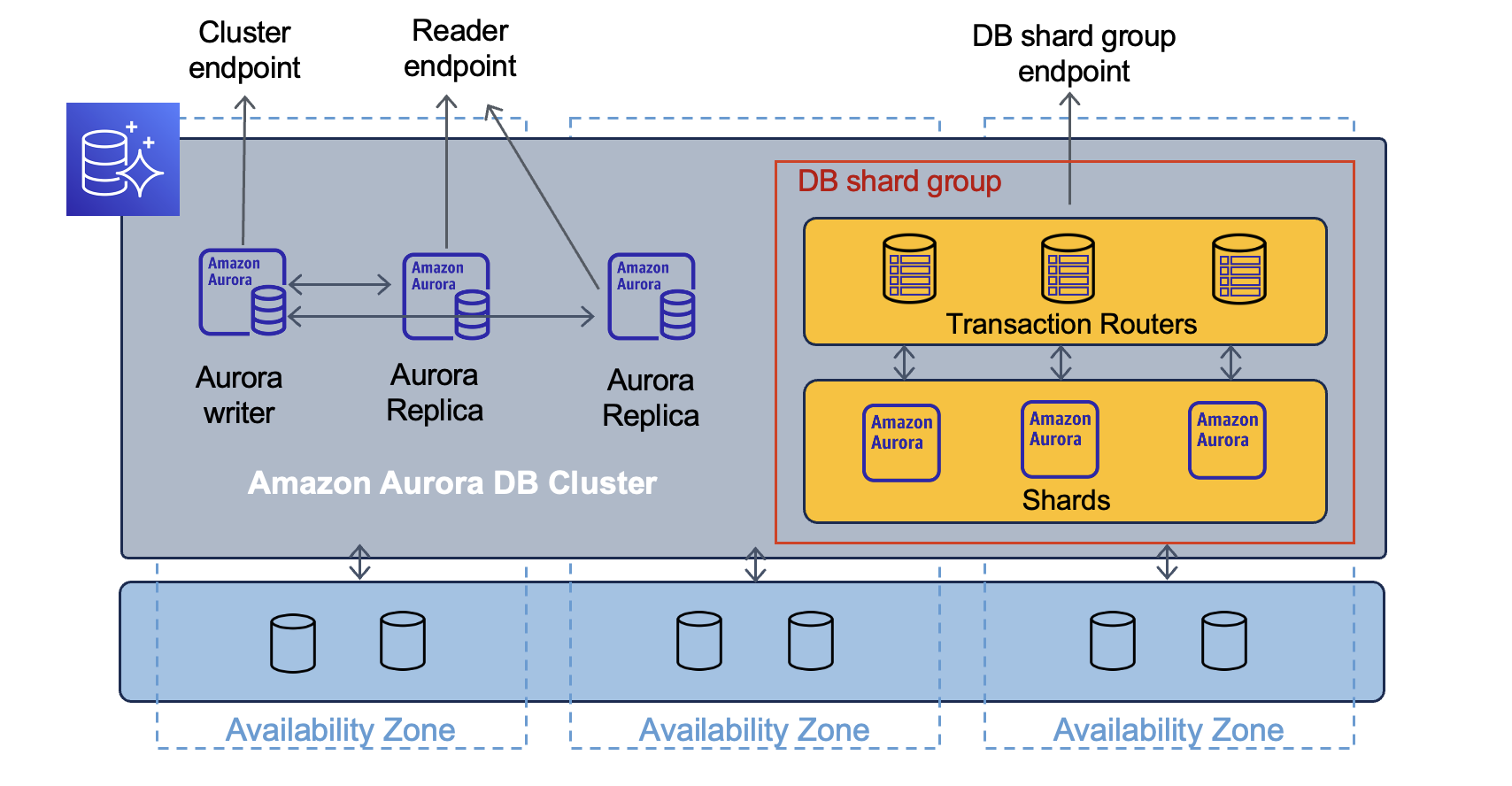
6. aurora limitless database有三个创新点:
(1) 新的路由层。首先,aws设计了新的路由层,尽可能减少对数据库状态的依赖。路由节点只需要很少的缓慢变化数据来理解数据库的schema和分片分区方案。保持此层轻量级意味着我们能够快速扩展,并且可以跨多个可用区高效运行,无需客户管理复杂的复制。其次,每个路由节点实际上都是一个 Aurora 数据库。因此,aws可以跨多个数据库分片编排复杂查询并合并结果,允许用户在整个分片数据库中运行分布式事务。
(2)新的分片管理方式。基于之前提到的grover和Caspian,来进行分片节点的管理。可以通过grover来克隆节点,在克隆之后,通过caspian来调整内存(缩小内存),二者合作实现无缝扩展分片节点。
(3)分布式数据库的时间同步是一个非常重要的事情(前几天老白刚刚写过一个Oceanbase的调优的文章)。为了提高分布式事务的效率,aws做了自己的时间同步服务(和时间同步硬件),这个时间同步,是利用aws的Nitro芯片,通过发送脉冲信号,在硬件级别实现的同步,绕过了操作系统、驱动程序、网络缓冲。
看完了视频,我不禁概括:
首先,aws把aurora架构玩出了不少花,通过grover,他可以类似mongodb效果做出来documentdb,他可以类似citus效果做出来aurora limitless database,将serverless推向极致。
但这种创新,不是reinvent mongodb altas,不是reinvent postgresql citus,而是一种基于aws自身技术沉淀之后的创新。他的技术创新,是有迹可循,可以看到成长轨迹,可以看到其变化逻辑。
但,既然是基于grover的共享文件系统,那么成也aurora败也aurora,它能做跨az的架构,是无法做跨region的架构(mongodb altas可以)。
其次,在另外的文章中有看到,如果是做分片,需要指定表是sharded tables还是reference tables,目前大部分的分布式数据库,分片模式基本都在这么做。开发需要留意,并不是完全无改造成本。
第三,比较疑惑的地方是,视频中提到“Amazon Aurora Limitless Database 提供单一接口,并自动在多个数据库分片间扩展和复制数据。”,但是在架构示意图中,却有3个接入点:cluster endpoint、reader endpoint、DB shard group endpoint。 那么应用的连接,是需要事先指定endpoint吗?还是能自动根据负载切换的,也就是说,对应用来说只需要一个endpoint?
第四,aurora limitless database是已经postgres supported,mysql is coming soon,aws已经迈入了关系型的分布式数据库轨道,oracle你还在观望吗?你的sharding后续还会发力吗?
最后,阿里云这个事情上跟进,应该会比较快吧? polardb也有阿里自己写的polarFS,类似grover,也有自己的智能管控平台das,类似caspian,而且阿里云已经有基于mysql的polardb-x了。期待哪位同学能进行aurora limitless database VS polardb-x的对比。 (但我觉得,追求的目标上的差异,是会导致两款数据库在设计思路上的差异,aurora limitless明显是奔着serverless去的, 而polardb-x,我感觉好像是为了迎战国内分布式数据库的产品(TDSQL、Oceanbase、TiDB等),为了分布式而分布式?)

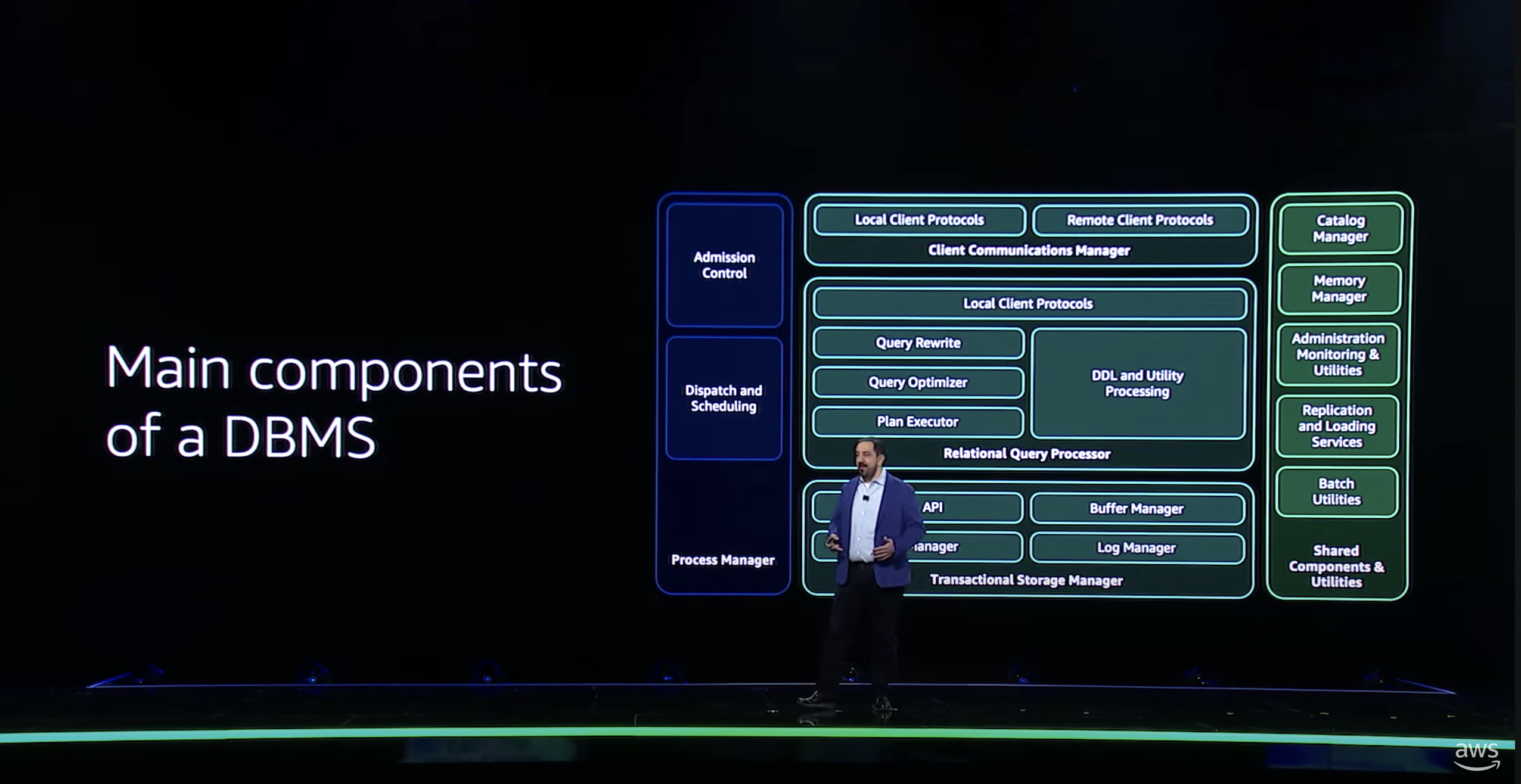






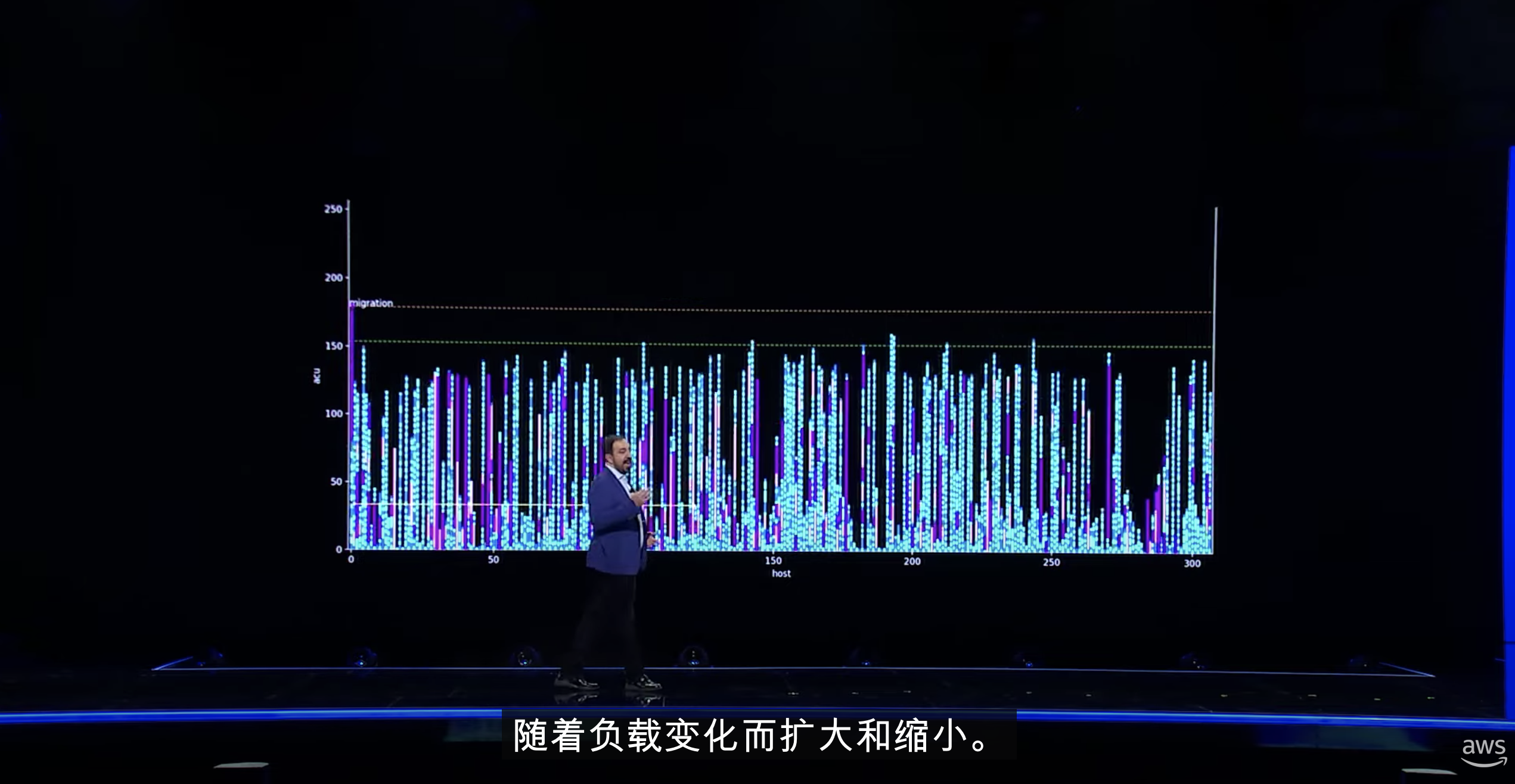












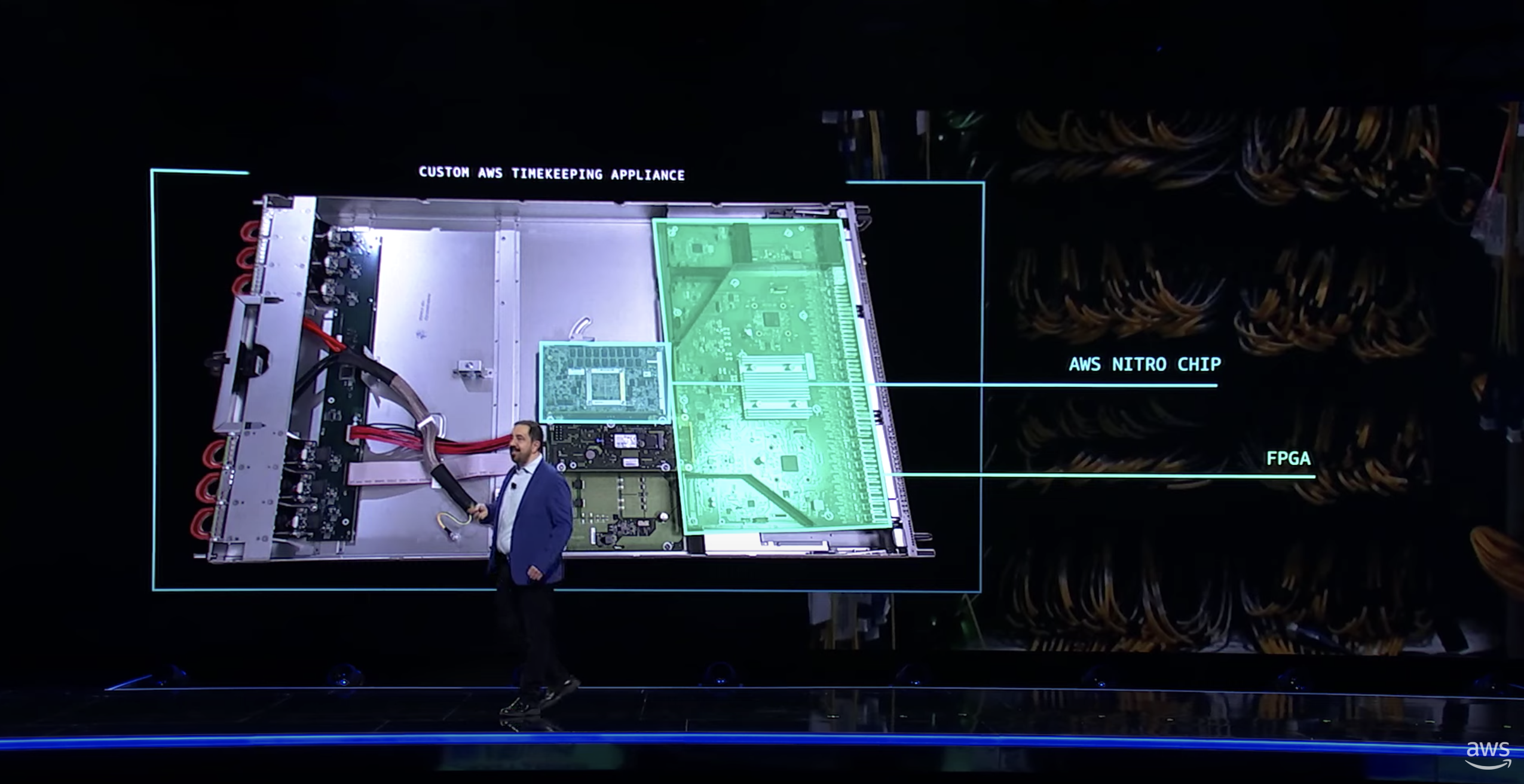

参考:
Join the preview of Amazon Aurora Limitless Database
Announcing Amazon Aurora Limitless Database
数据规模拓展无极限,引领 Serverless 构建之路丨re:Invent 2023 首日主题演讲重磅发布
AWS re:Invent 2023 – Monday Night Live Keynote with Peter DeSantis