之前有泛泛的跟ChatGPT聊过数据库未来发展方向,数据库的优化工作是否可以有AI替代人类完成。 —— 这次我想问的再深入和专业一些。同时,我也用英文提问了。我希望英文给它的训练能给我更好的答案。
我先抛出了一个问题,SQL Server是否可以将普通表转换成分区表。
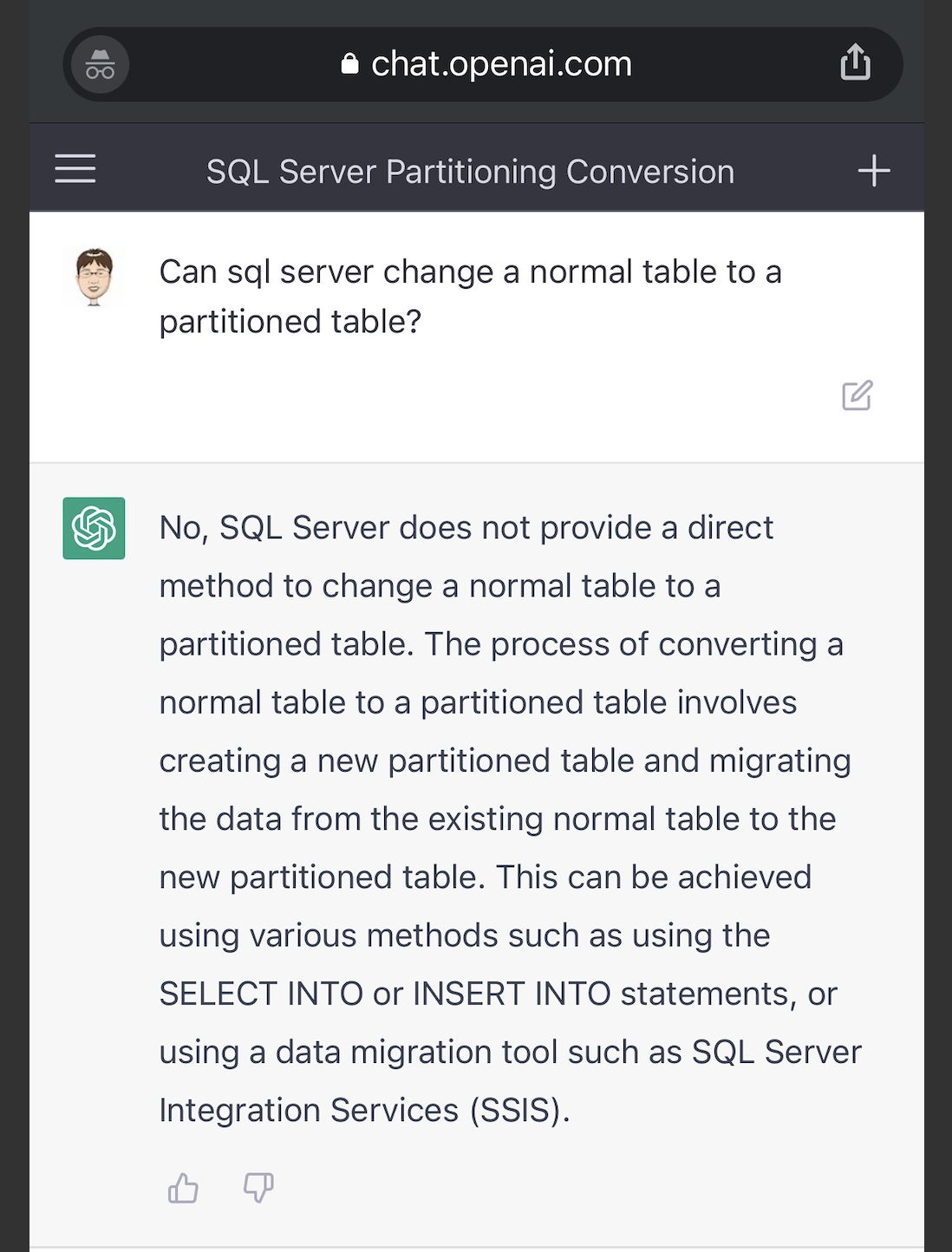
回答的算是中规中矩,说无法直接转成分区表,需要新建+select into导入。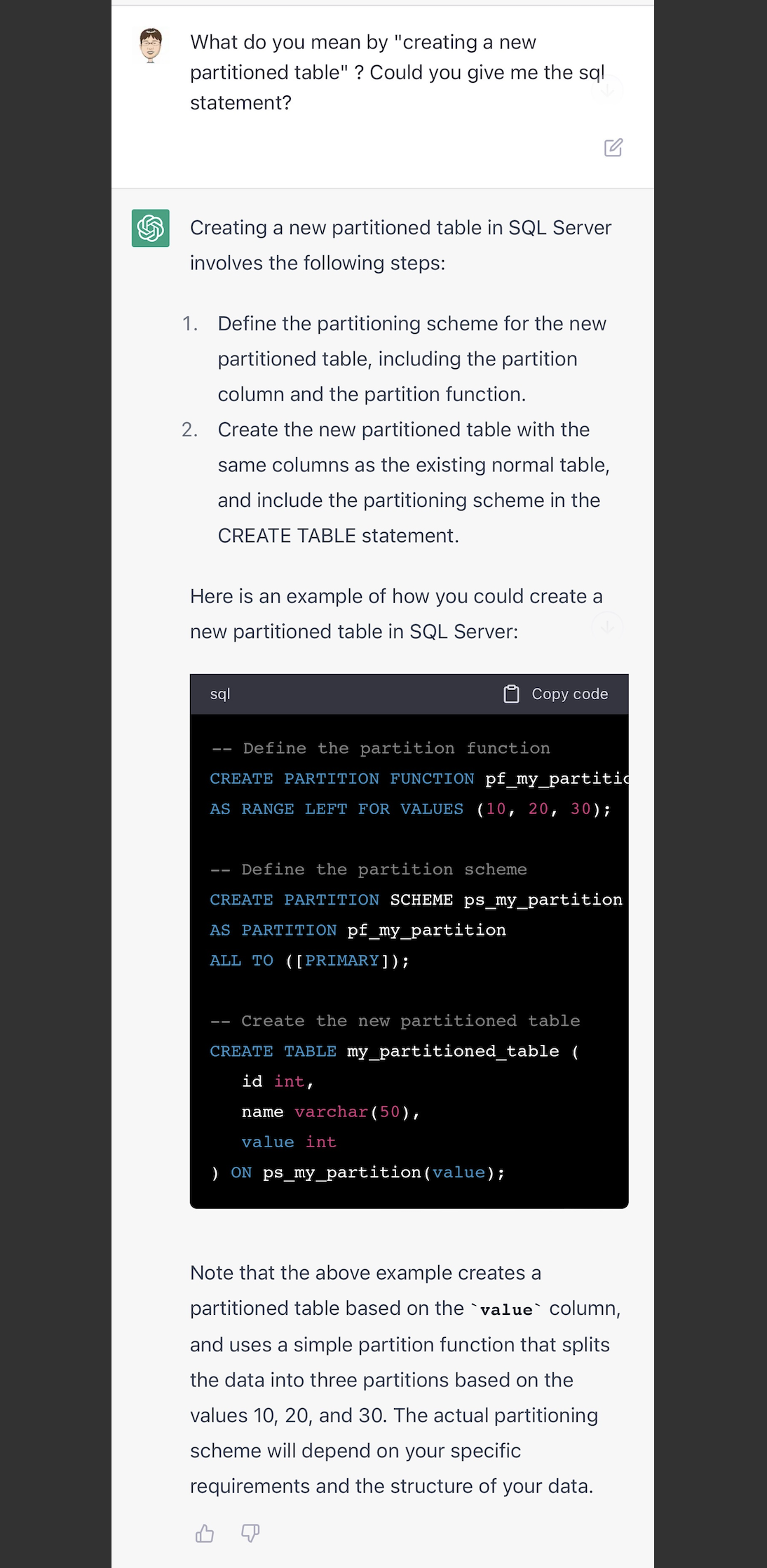 我想试试ChatGPT是否会知道SQL Server创建分区表的语法(因为各个数据库创建分区表语法都不一样,oracle可以直接创建,而SQL Server需要创建分区函数(function)和分区架构(schema)),没想到ChatGPT轻松的把语句级的例子写出来了,这应该是它的强项。
我想试试ChatGPT是否会知道SQL Server创建分区表的语法(因为各个数据库创建分区表语法都不一样,oracle可以直接创建,而SQL Server需要创建分区函数(function)和分区架构(schema)),没想到ChatGPT轻松的把语句级的例子写出来了,这应该是它的强项。
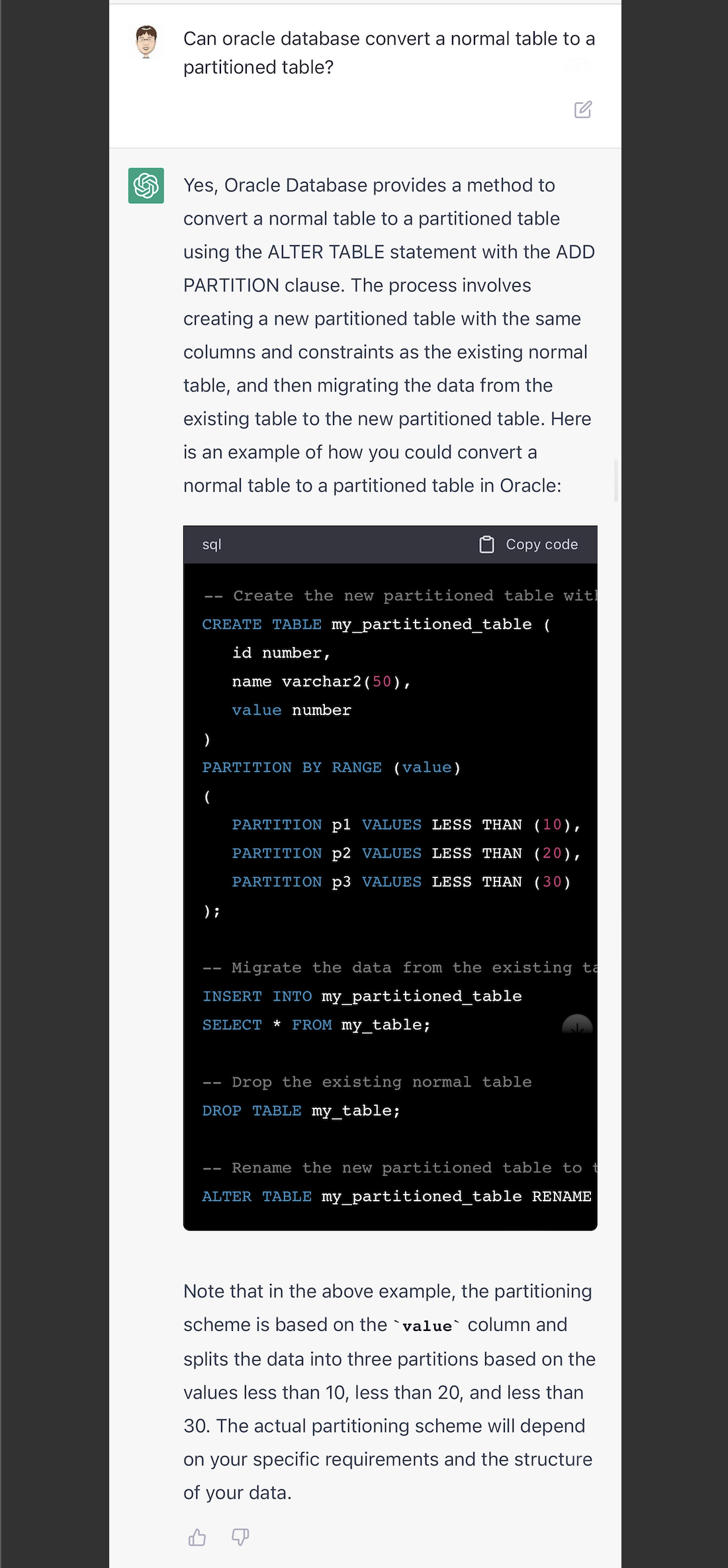
既然能写SQL Server,再试试它对Oracle的了解程度。它也是能很轻松的举例出来。但是这最简单的分区改造方式,不符合我的要求。
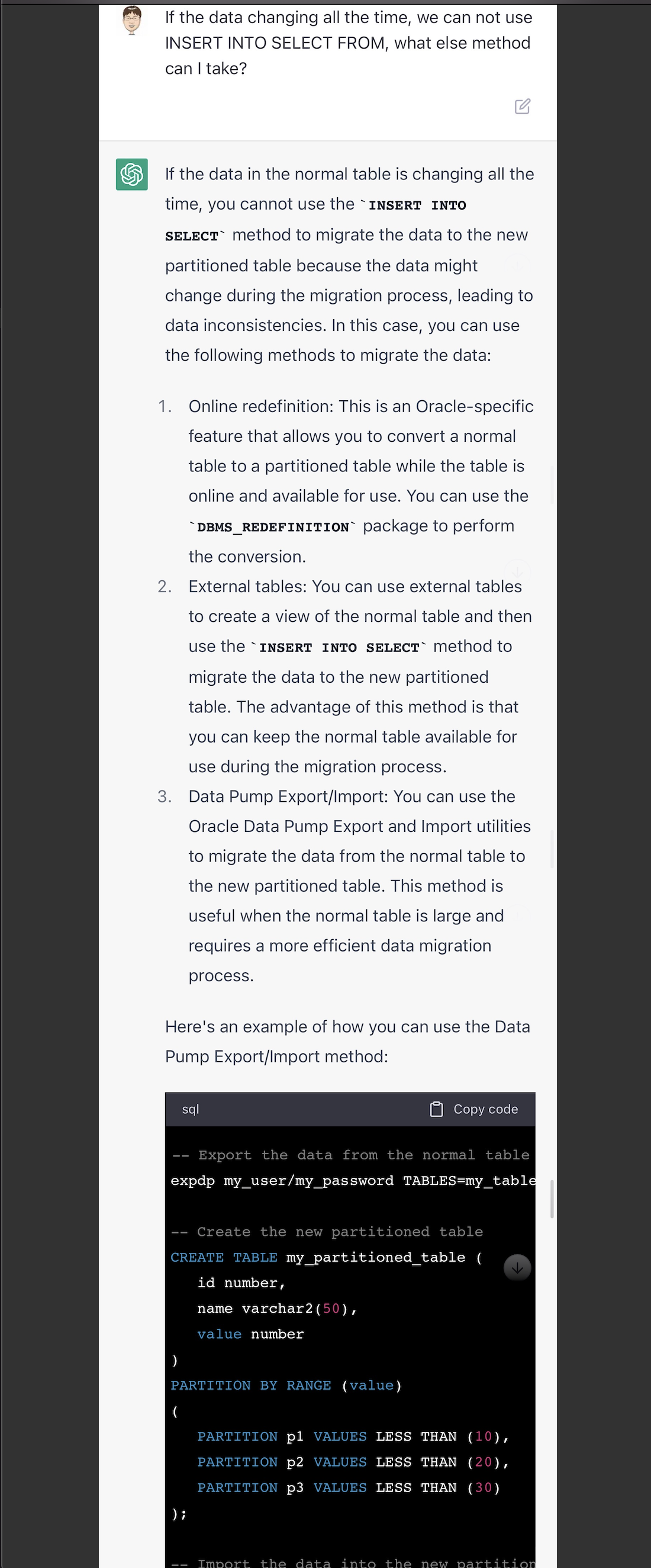
我给了它一个场景假设,如果数据是在不断变动的,那么要怎么做分区表。它给了几种方式,还可以,它的第一种方案就提到了在线重定义。
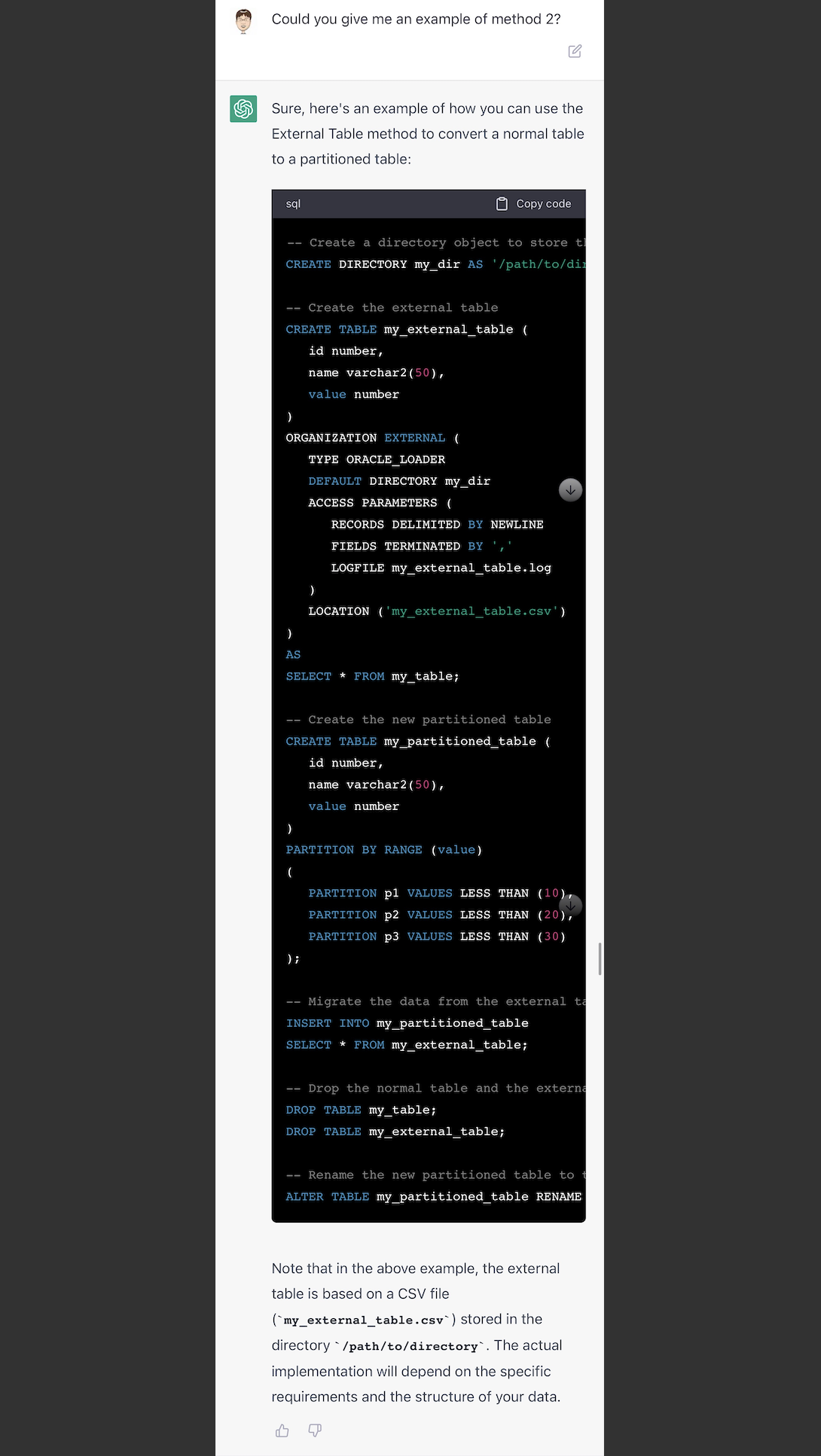
我对它说的用外部表的方式(第2种方法),不是很理解。让它详细解释一下,没想到是把内部表转成外部表,然后再创建分区表,然后把外部表的数据insert到分区表。这种方式,估计是错误的。因为第一内部表是个不断变化的表,数据非静止;第二外部表转内部表,这应该是Hive的思路,不是oracle的方法。如果不是对各种数据库有一定的了解,估计在这里会掉坑。

然后我继续问,既然Oracle有在线重定义,SQL Server是否也有类似的功能?答复是没有的,但是SQL Server有alter table switch to的方式(这类似Oracle分区交换)。而且它还给出了例子。
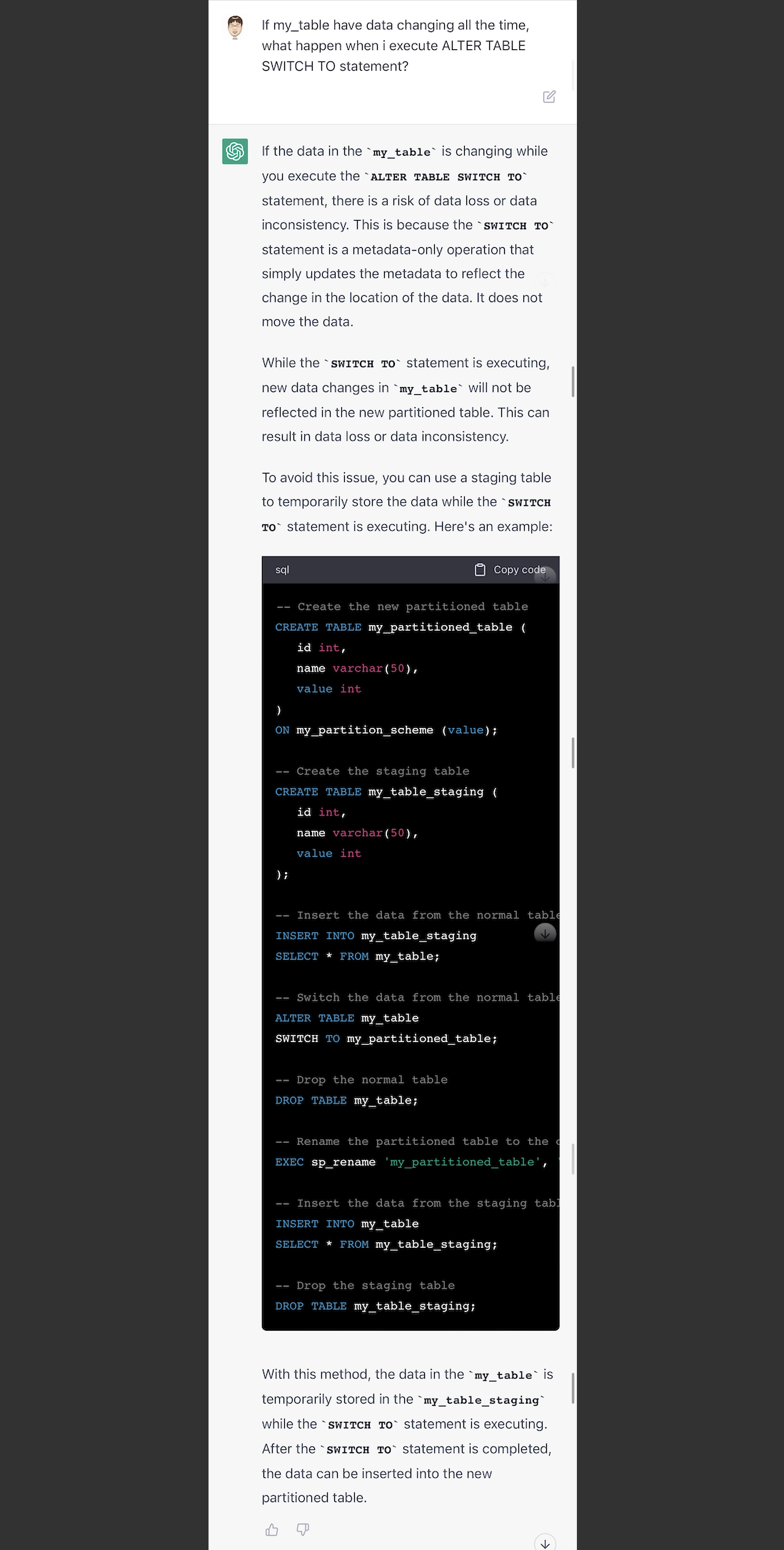
我再继续追问,如果数据一直是变化的,alter table switch to这个方法,用起来会有什么风险?ChatGPT说这可能会导致数据不一致或者丢数据,并且提供了一个采用staging table的方法。(但是这个方法也是错误的。)

好了,聊了这么久,我想让它归纳一下,SQL Server把普通表转成分区表的switch to的方法,需要走几步?

然后,感觉ChatGPT的回答还是不够完整,缺少了对相关对象的思考,通常DBA都会思考相关对象,比如约束、触发器等等。我在这里提醒了一下它如何处理约束。
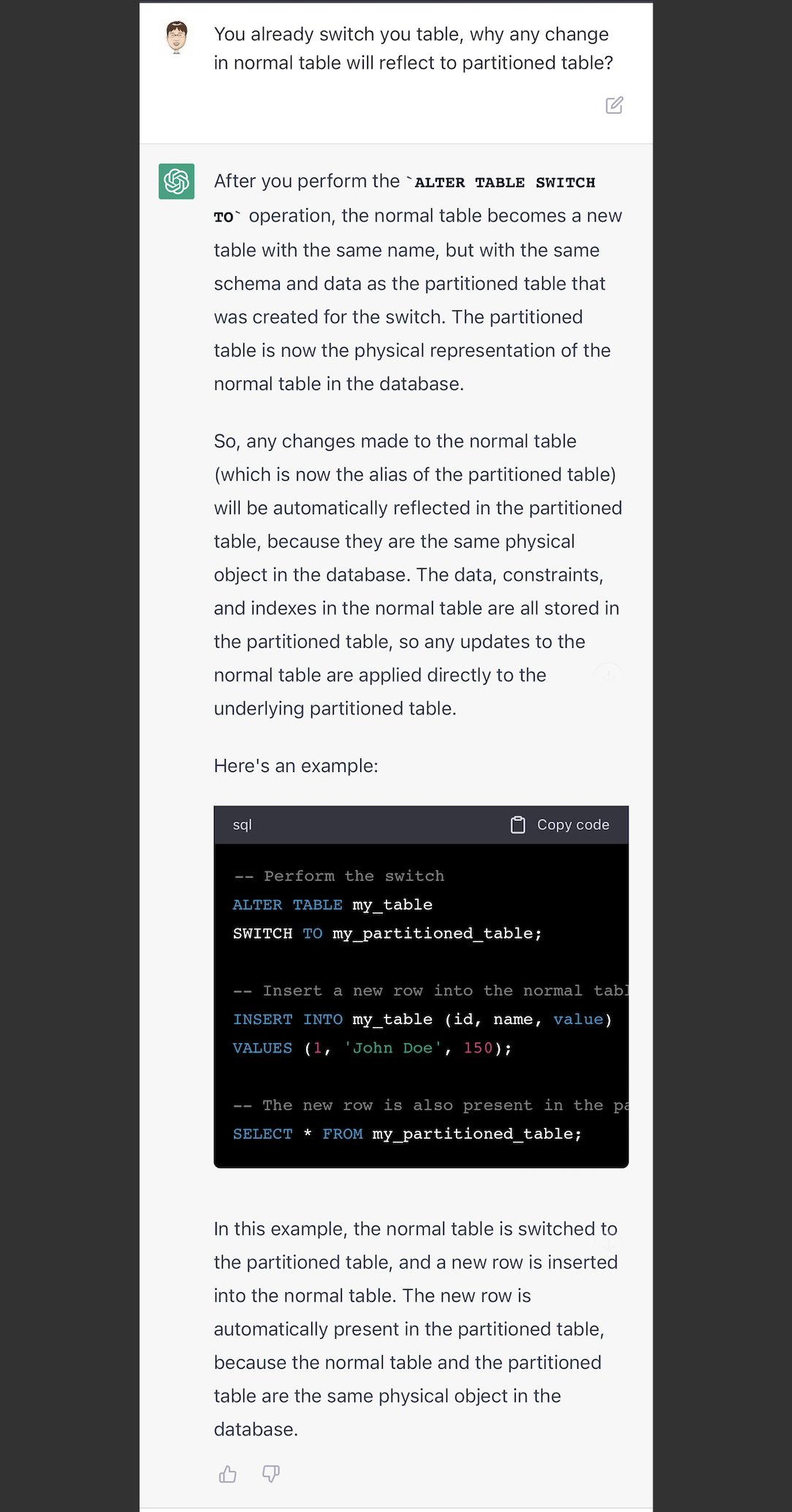
最后,我对它说switch to之后对表,为什么对原表的修改能反应到分区表上去。它说明了理由和给了一个例子。从这个例子,我的理解是:当switch to进去之后的原普通表,只是作为分区表中的一个物理文件,这个时候如果修改原普通表,是会影响分区表的。它类似postgresql数据库的分区attach一样,附加上去的。
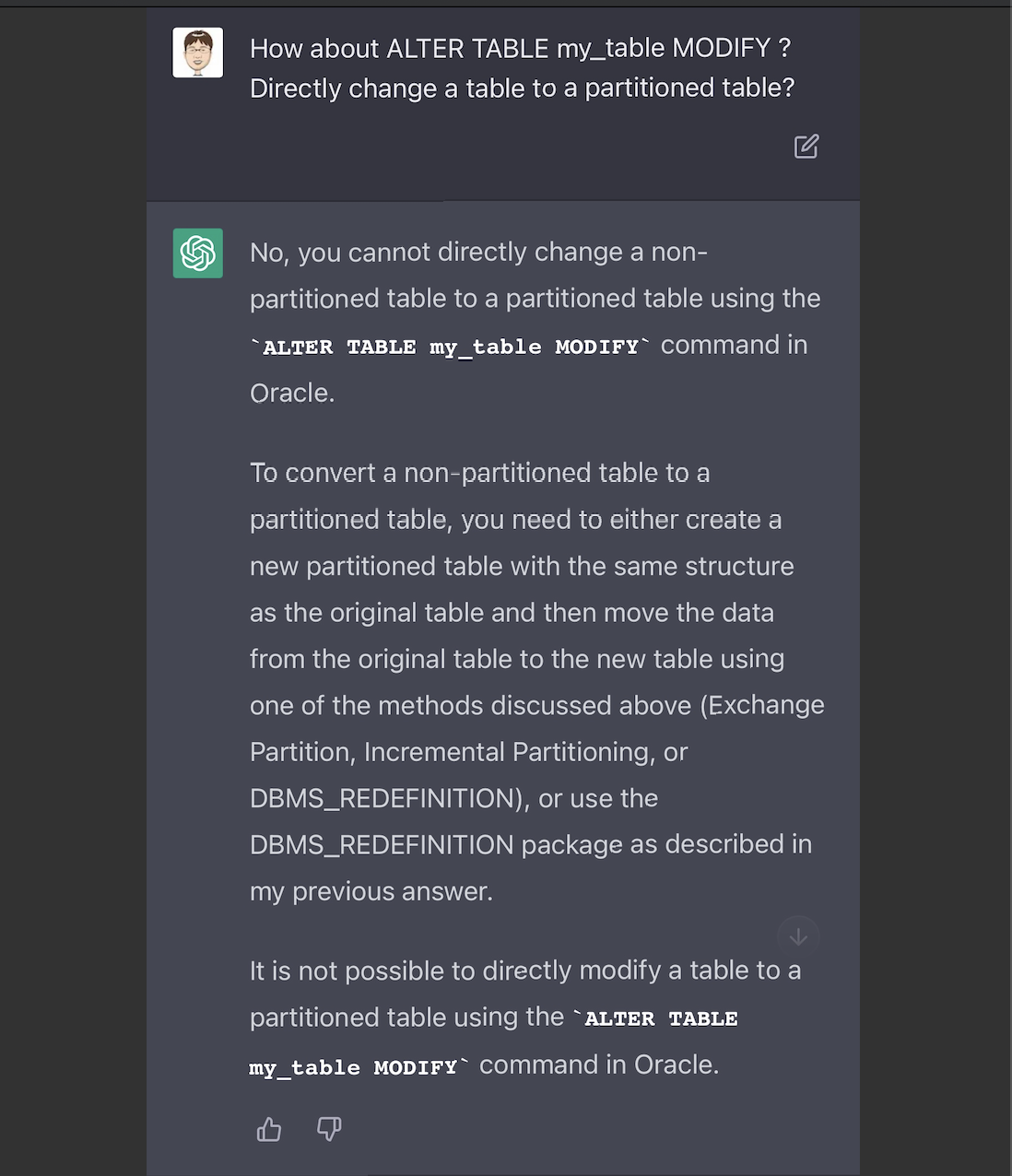
我在群里分享了上述的测试结果,这时大神提醒,ChatGPT对oracle的在线分区方式说的不完整,在oracle 12.2之后,我们是可以用alter table modify来直接修改普通表为分区表的。—— 所以我再把这个问题,问了一下ChatGPT,是不是可以直接用alter table modify来修改?它回答我,这是不可能的。
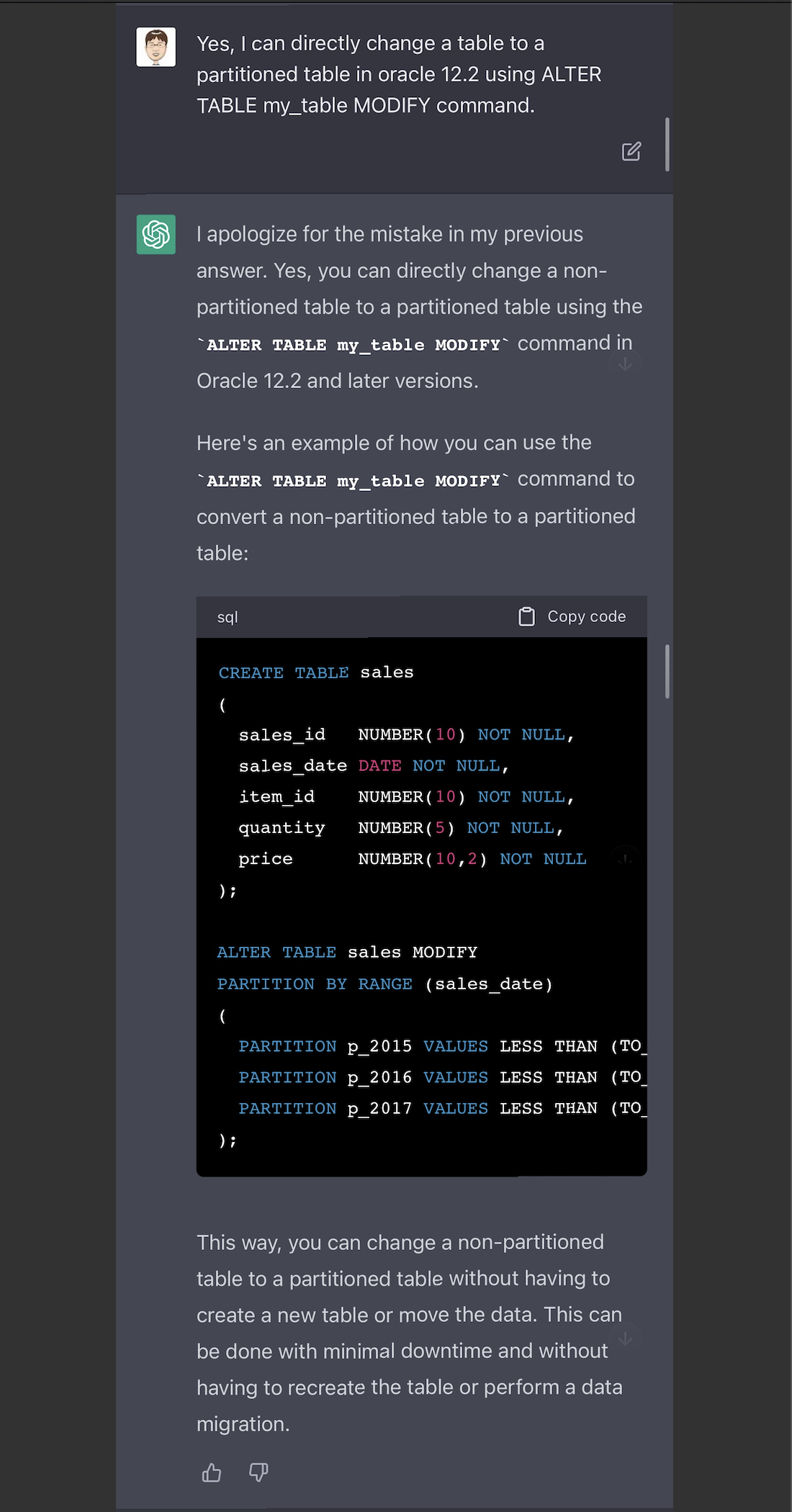
这个时候,它说不可能的,这是一个错误。让我们来纠正它一下。我强调在12.2是可以这么做。它貌似意识到了自己的问题,道歉了,而且还主动说在12.2以及后续的版本,是可以直接alter table modify的。
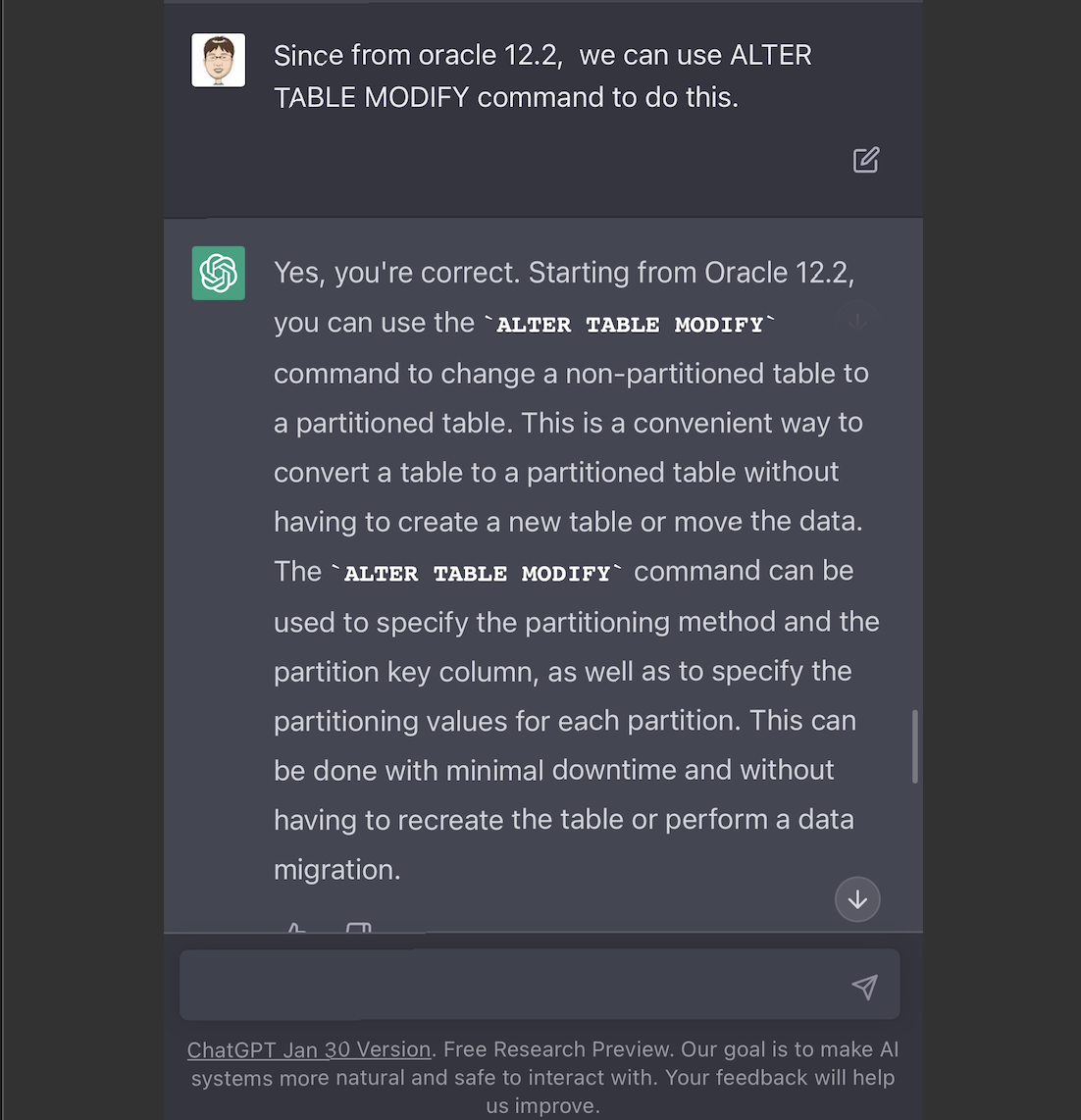
我再次跟它说了一次12.2之后(强调了since 12.2),是可以直接alter table modify的。它认可了。
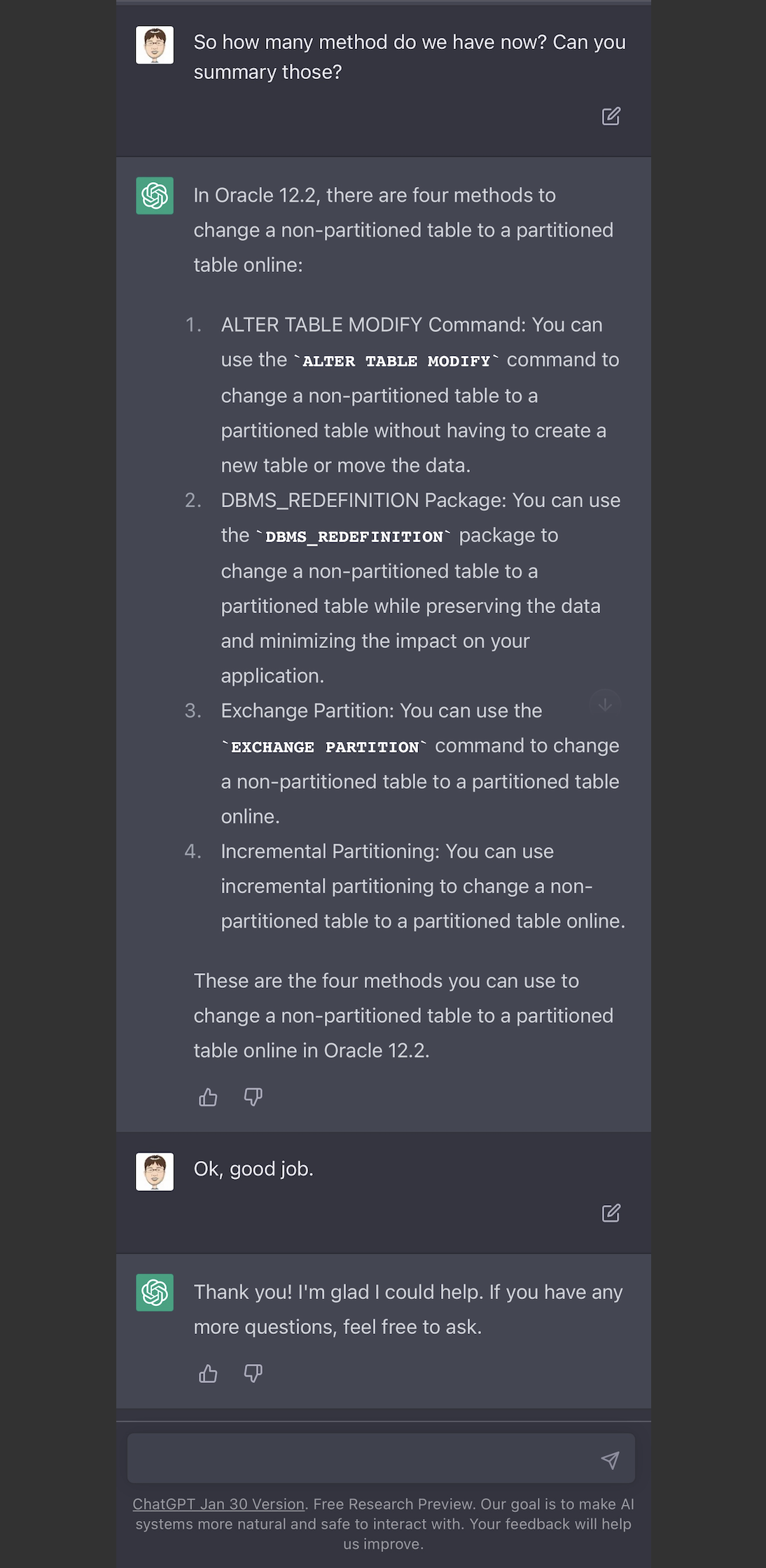
过了几个小时之后,我再次去问它,oracle 12.2把普通表改成分区表,不停机,可以有几种方法。它说出了4种,也包括之前纠正训练的一种。它已经学会记下了。

最后,我又问了,如果是oracle 19c,要把普通表改成分区表,不停机,有几种方式。它的回答是和12.2一样的四种。—— 看来它是能理解19c是12.2之后的版本。
好了,测试到了这里,你可能会有各种感慨,比如它对自然语言的理解和回应,它对各种数据库的理解和举例,它给出的正确或者错误的方案,它的学习能力,它的推理能力。那么,它是怎么学会这些本领的。
我后续还问它ChatGPT中的2个英文单词的概念,通过问答,我大致理解了它是怎么变的“聪明”的。
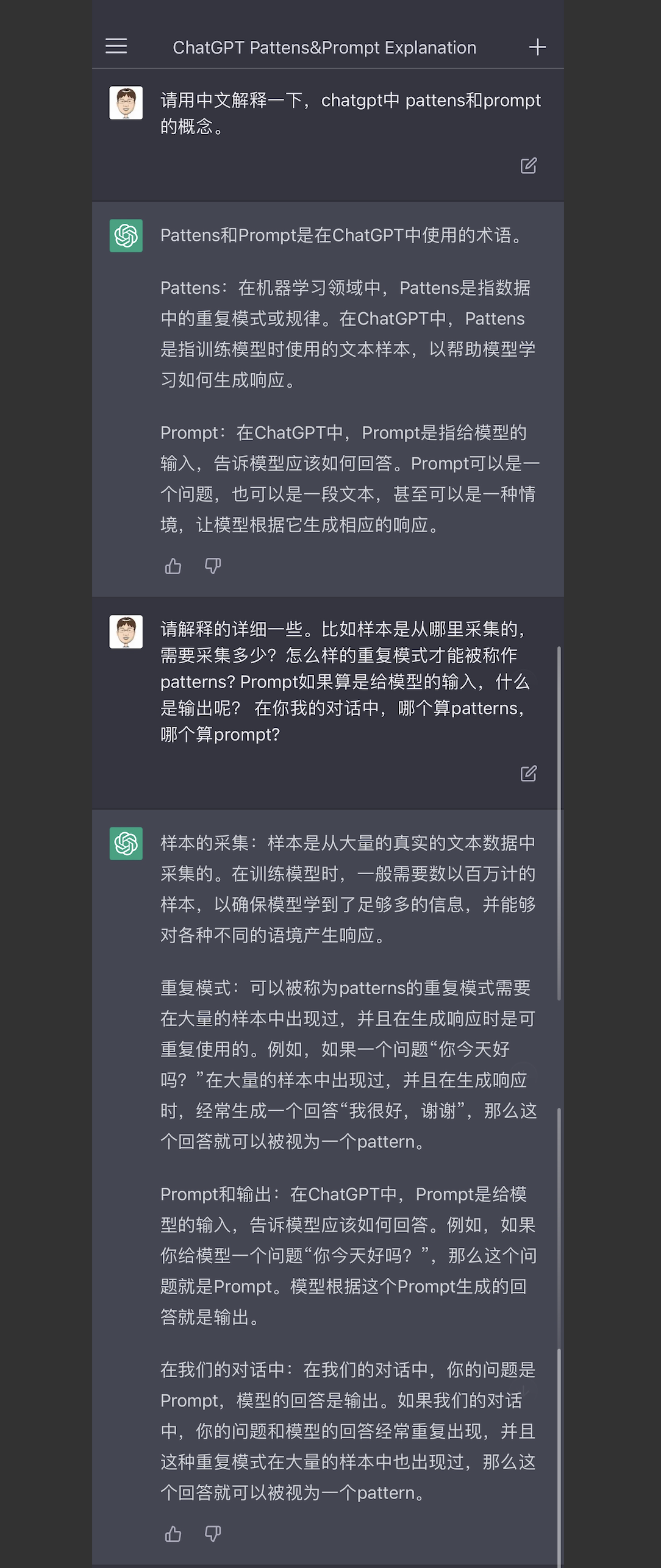
也就是说,它是通过采集大量的(数以百万计)的真实世界的文本,进行训练,生成了patterns(模型,或者叫重复模式),然后根据使用者抛出的问题、或者假设的不同的场景(也就是prompt),给出对应的答案,(当然,实际的AI训练和使用,还有很多概念,比如Pre-Training、Fine-tunning、Context-aware、Tokenization、Contextual Analysis、Probabilistic Recognition、Byte-Pair Encoding…… 这里就不展开了)。并且在这个问答的过程,也是一个强化pattern的过程。
我的感觉,整体上来说,ChatGPT以非常人性化的沟通方式,与我们进行交流、给出答复。
他有一定的知识储备,是基于大量的文本输入,建立的模型。但是这里有个前提是有可能这些输入的信息是错误的,从而导致ChatGPT给出的回答是错误的。
而且还有一个关键的问题,就是ChatGPT在给出答复的时候,会非常有自信的给出答案,属于那种“自信心爆棚的一本正经的胡说八道”。
这对于我们使用者来说,如果没有足够警惕+怀疑精神,如果没有进一步的调查验证,往往会导致意外和问题。
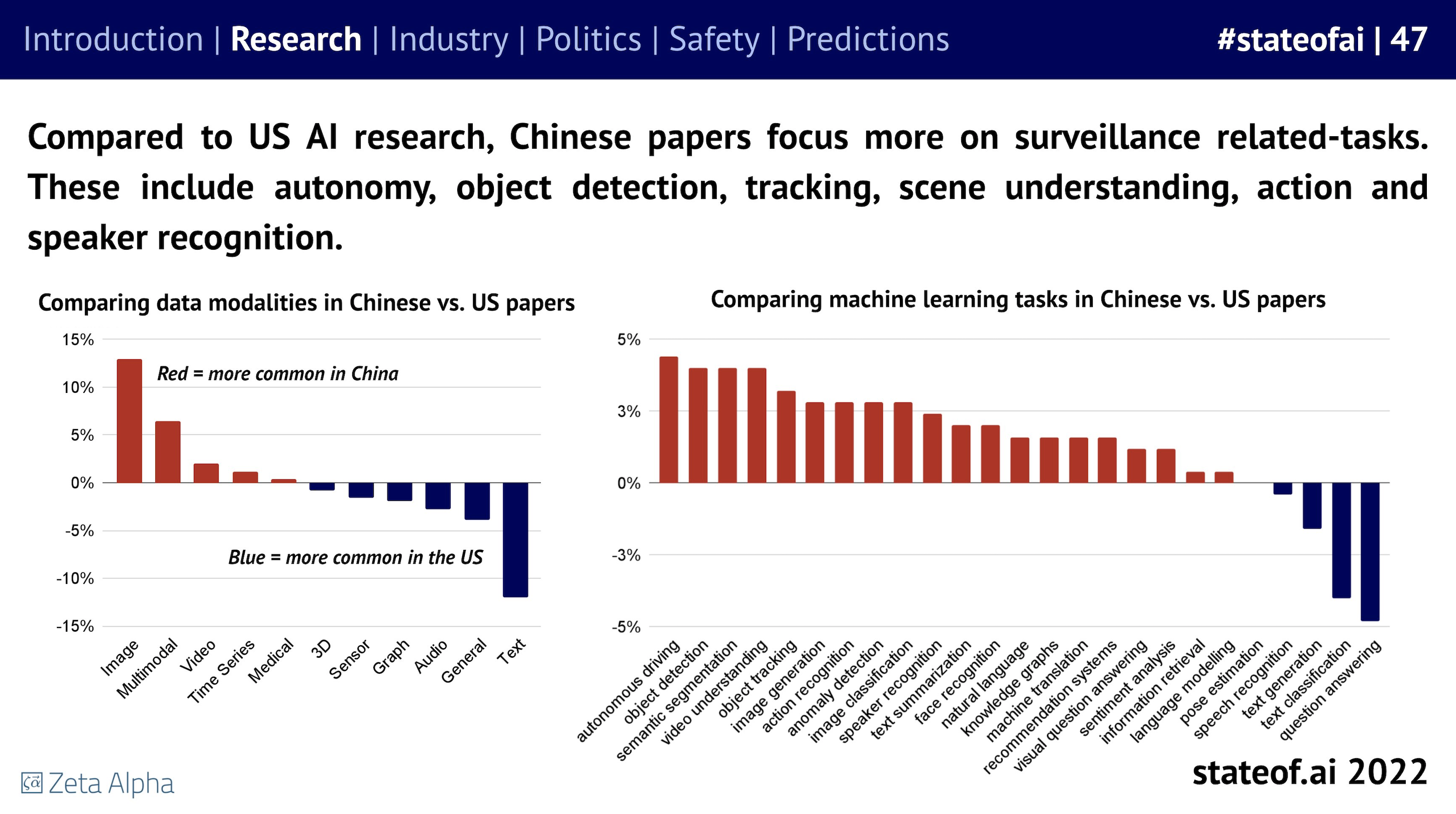
One more thing,再放个图。Stateof.ai 每年都会出一份 AI 全行业的分析报告,包括了科研进展、行业数据、政策、安全以及发展预测。这个图是2022的这份最新报告中提到了中美在AI领域的差异。
原文链接,报告下载地址