十一期间,读了这本《混沌工程:Netflix系统稳定性之道》。

这本书很小,但是带来的很多理念还是新的。以下,是一些感悟:
(1)混沌工程更多是面向分布式系统,微服务,云原生的系统。本身就是假定系统是不稳定的,程序是需要面向失败的设计(Design for failure)。
(2)混沌工程有点像测试,但它不是传统测试,不是故障注入。故障注入的故障是可预知的,可枚举的。而混沌工程是探索性的,他不仅仅可以注入错误,还能注入正常但激增高于平常的流量,从而判断在降级熔断某个系统的时候,是否对其上下游的系统有相关影响,是否会引发雪崩现象。
(3)混沌工程是复杂系统的改进学科,有2个前提,如果已经很明确某个操作会导致故障,那么这个操作就仅仅是故障注入,而不是混沌工程;如果没有配套的监控系统,那么也无法量化观测。
(4)康威定律:”设计系统的架构受制于产生这些设计的组织的沟通结构。”—— 即系统设计本质上反映了企业的组织机构。系统各个模块间的接口也反映了企业各个部门之间的信息流动和合作方式。阿里能搞中台,google能搞SRE,Netflix能搞无运维人员的系统运维,都是其内部组织架构的沟通方式,在IT系统中的体现。
(5)传统架构师负责理解组织中的各个部分如何组成系统以及他们是如何交互,但是大型分布式系统中人类难以胜任这个角色(见下)。微服务牺牲了可理解性和掌控,这是混沌工程发挥作用的地方。

(6)牛鞭效应:在一条供应链中,消费市场需求的微小变化如何被一级级放大到制造商、首级供应商、次级供应商等。例如计算机市场需求预测轻微增长2%,转化到戴尔(制造商)时可能成了5%,传递到英特尔(首级供应商)时则可能是10%,而到了替英特尔生产制造处理器的设备商(次级供应商)时则可能变为20%。简言之,越是处于供应链的后端,需求变化幅度越大。由于这种需求放大效应的影响,供应方往往维持比需求方更高的库存水平或者生产准备计划。牛鞭效应不仅仅发生在供应链中,在底层硬件的微小波动,都会造成上层操作系统、数据库系统、应用程序的越来越大的波动。比如vmware做vmotion丢1、2个包,导致数据库集群认为主机通信有问题,进而引发集群切换,切换期间数据库不可用,导致业务中断好几分钟。另外,牛鞭效应,Bullwhip effect,不是Bull Penis effect。:-P
(7)哪些服务有状态:数据库服务(保持配置设置,或者记录生产数据),配置服务(静态配置,或者动态配置如etcd),隐藏的状态(如auto scaling的个数,集群状态,交换机路由器)。混沌工程的工具:FIT, chaos monkey(破坏节点),Chaos Gorilla(破坏整个az),chaos kong(破坏整个region),chaos lambda,Blockade, ChAP, ChaosBlade
(8)和传统的测试不同,混沌工程需要靠近生产环境,需要在生产或靠近生产的环境中实验。不愿意在生产上实验的原因是,看到系统还不具备弹性能力,害怕不能立即终止,害怕爆炸半径过大。
(9)混沌工程的原则:建立稳定态的假设;用多样性的现实世界事件做验证;在生产环境进行实验;自动化实验以持续运行;最小化爆炸半径。
(10)混沌工程的成熟程度,Netflix总结了两个维度,一个是复杂度,一个就是接受度(书上叫熟练度和应用度,但是我觉得还是翻译成复杂度和接受度比较信达雅)。
前者表示的是混沌工程能有多复杂,而后者则表示的是混沌工程被团队的接受程度。
(10.1)复杂度分成4个等级:
初级
简单
复杂
高级
(10.2)接受度分成4个等级:
在暗处
有投入
接受
文化
(11)混沌工程从2010年演进发展的时间线:
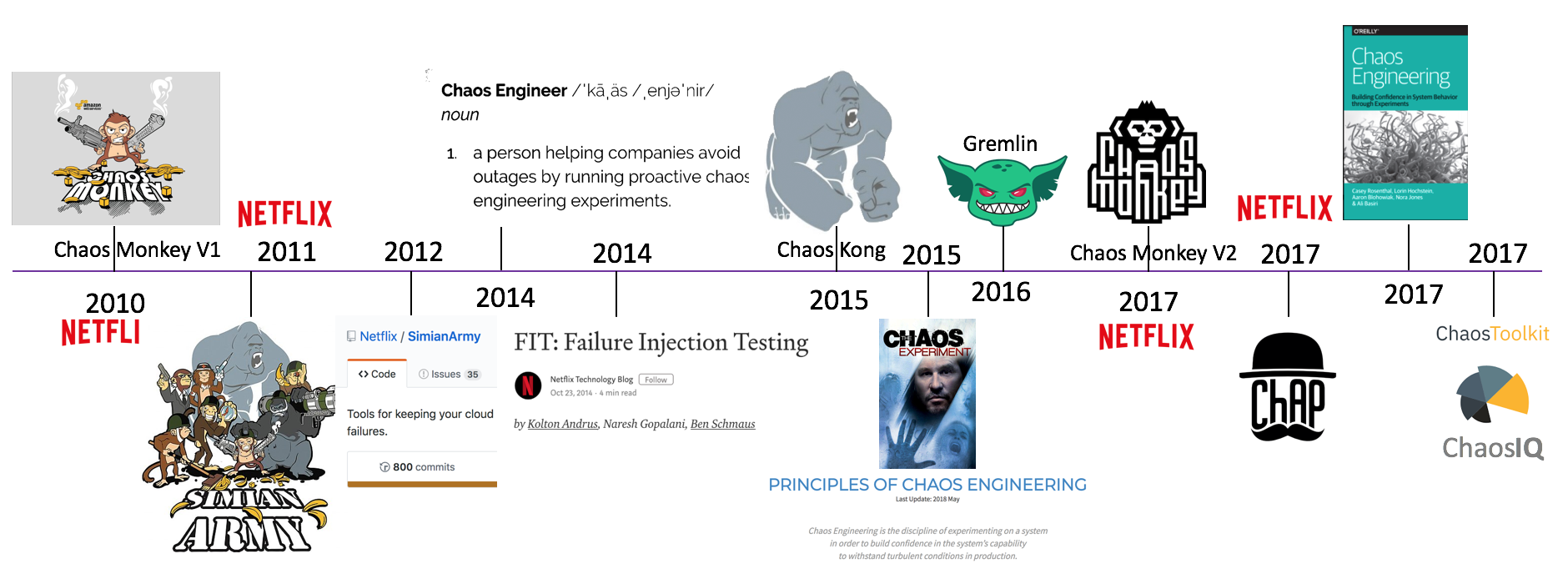
2010年 Netflix 内部开发了 AWS 云上随机终止 EC2 实例的混沌实验工具: Chaos Monkey
2011年 Netflix 释出了其猴子军团工具集: Simian Army
2012年 Netflix 向社区开源由 Java 构建 Simian Army,其中包括 Chaos Monkey V1 版本
2014年 Netflix 开始正式公开招聘 Chaos Engineer
2014年 Netflix 提出了故障注入测试(FIT),利用微服务架构的特性,控制混沌实验的爆炸半径
2015年 Netflix 释出 Chaos Kong ,模拟AWS区域(Region)中断的场景
2015年 Netflix 和社区正式提出混沌工程的指导思想 – Principles of Chaos Engineering
2016年 Kolton Andrus(前 Netflix 和 Amazon Chaos Engineer )创立了 Gremlin ,正式将混沌实验工具商用化
2017年 Netflix 开源 Chaos Monkey 由 Golang 重构的 V2 版本,必须集成 CD 工具 Spinnaker 来使用
2017年 Netflix 释出 ChAP (混沌实验自动平台),可视为应用故障注入测试(FIT)的加强版
2017年 由Netflix 前混沌工程师撰写的新书“混沌工程”在网上出版
2017年 Russell Miles 创立了 ChaosIQ 公司,并开源了 chaostoolkit 混沌实验框架
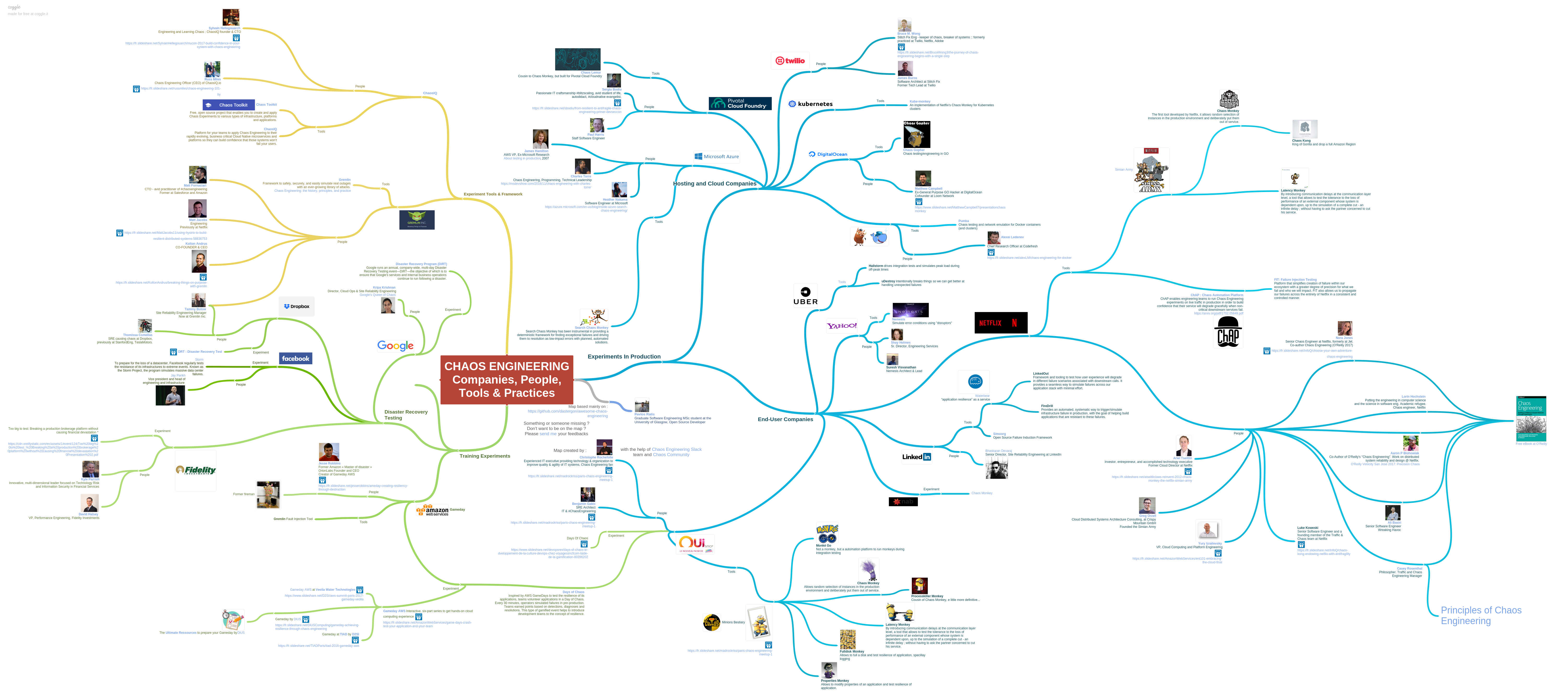
(12)Chaos Engineering: Compaines, People, Tools & Practices(原图,带链接,点击此处)
参考:
混沌工程简介
AWS云上混沌工程实践之启动篇
混沌工程实践经验:如何让系统在生产环境中稳定可靠
阿里巴巴在混沌工程领域的实践和思考
延伸阅读:
Intro to Chaos Engineering
Resiliency through Failure – Netflix’s Approach to Extreme Availability in the Cloud
Mastering Chaos – A Netflix Guide to Microservices
Getting started with Chaos Engineering – Paul Stack
AWS 云上混沌工程实践之对照实验设计和实施 黄帅
AWS云上混沌工程实践之可行性评估篇
鲜为人知的混沌工程,到底哪里好?
.
一条评论
网络上没有免费pdf,看了你的总结,感觉还不错。