添加或者删除shard,是shard的数量发生变化,叫做re-shard。re-shard会导致chunk的挪动(chunk migration),re-shard的chunk migration是将原来的chunk的序号大的部分,移动到新node上。示意图如下:
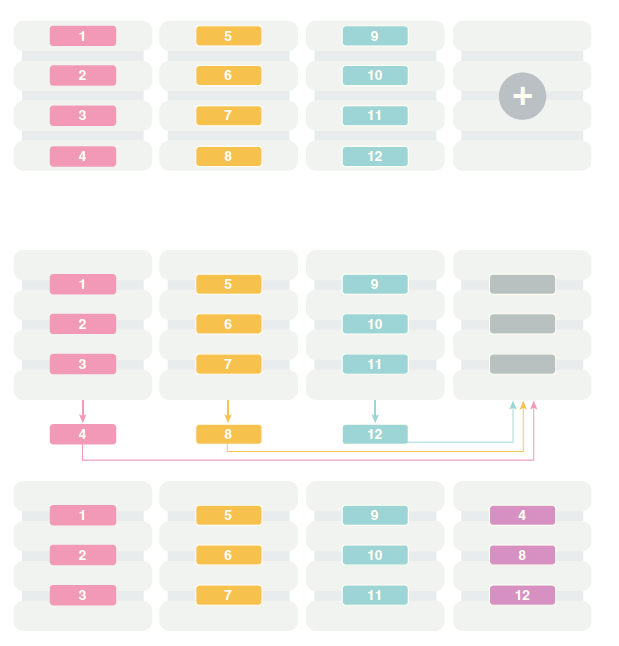
我们来发起一次添加shard节点,做re-shard:
1. 检查初始状态,在shardcat主机:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
[oracle12c@sdb1 ~]$ gdsctl GDSCTL: Version 12.2.0.0.0 - Beta on Mon Nov 07 10:52:30 CST 2016 Copyright (c) 2011, 2015, Oracle. All rights reserved. Welcome to GDSCTL, type "help" for information. Current GSM is set to SHARDDIRECTOR1 GDSCTL>set gsm -gsm SHARDDIRECTOR1 GDSCTL>connect mygdsadmin/oracle Catalog connection is established GDSCTL> GDSCTL> GDSCTL>config shard Name Shard Group Status State Region Availability ---- ----------- ------ ----- ------ ------------ sh1 primary_shardgroup Ok Deployed region1 ONLINE sh2 primary_shardgroup Ok Deployed region1 ONLINE GDSCTL> [oracle12c@sdb1 ~]$ cat /etc/hosts # Do not remove the following line, or various programs # that require network functionality will fail. 127.0.0.1 testdb2 localhost.localdomain localhost 192.168.56.21 sdb1 sdb1.localdomain 192.168.56.22 sdb2 sdb2.localdomain 192.168.56.23 sdb3 sdb3.localdomain 192.168.56.24 sdb4 sdb4.localdomain 192.168.56.25 sdb5 sdb5.localdomain [oracle12c@sdb1 ~]$ |
2. 在新的shard node主机(sdb4)启动schagent
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
[oracle12c@sdb4 dbs]$ schagent -start Scheduler agent started using port 22991 [oracle12c@sdb4 dbs]$ [oracle12c@sdb4 dbs]$ schagent -status Agent running with PID 4585 Agent_version:12.2.0.1.2 Running_time:00:00:10 Total_jobs_run:0 Running_jobs:0 Platform:Linux ORACLE_HOME:/u01/ora12c/app/oracle/product/12.2.0/db_1 ORACLE_BASE:/u01/ora12c/app/oracle Port:22991 Host:sdb4 [oracle12c@sdb4 dbs]$ [oracle12c@sdb4 dbs]$ [oracle12c@sdb4 dbs]$ echo oracleagent|schagent -registerdatabase sdb1 8080 Agent Registration Password ? Oracle Scheduler Agent Registration for 12.2.0.1.2 Agent Agent Registration Successful! [oracle12c@sdb4 dbs]$ [oracle12c@sdb4 dbs]$ mkdir -p /u01/ora12c/app/oracle/oradata [oracle12c@sdb4 dbs]$ mkdir -p /u01/ora12c/app/oracle/fast_recovery_area [oracle12c@sdb4 dbs]$ |
3.在shardcat主机add shard node
|
1 2 3 4 5 |
GDSCTL>add invitednode sdb4 GDSCTL> GDSCTL>create shard -shardgroup primary_shardgroup -destination sdb4 -credential oracle_cred DB Unique Name: sh21 GDSCTL> |
4. deploy前检查状态:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 |
GDSCTL>config Regions ------------------------ region1 GSMs ------------------------ sharddirector1 Sharded Database ------------------------ shardcat Databases ------------------------ sh1 sh2 sh21 Shard Groups ------------------------ primary_shardgroup Shard spaces ------------------------ shardspaceora Services ------------------------ oltp_rw_srvc GDSCTL pending requests ------------------------ Command Object Status ------- ------ ------ Global properties ------------------------ Name: oradbcloud Master GSM: sharddirector1 DDL sequence #: 38 GDSCTL> GDSCTL> GDSCTL>config shardspace SHARDSPACE Chunks ---------- ------ shardspaceora 12 GDSCTL> GDSCTL> GDSCTL>config vncr Name Group ID ---- -------- sdb2 sdb3 192.168.56.22 192.168.56.23 192.168.56.21 sdb4 127.0.0.1 GDSCTL> GDSCTL>config shardgroup Shard Group Chunks Region SHARDSPACE ----------- ------ ------ ---------- primary_shardgroup 12 region1 shardspaceora GDSCTL>config shard Name Shard Group Status State Region Availability ---- ----------- ------ ----- ------ ------------ sh1 primary_shardgroup Ok Deployed region1 ONLINE sh2 primary_shardgroup Ok Deployed region1 ONLINE sh21 primary_shardgroup U none region1 - GDSCTL> GDSCTL>config chunks Chunks ------------------------ Database From To -------- ---- -- sh1 1 6 sh2 7 12 GDSCTL> chunk的情况,也可以在shardcat数据库里检查: SQL> select a.name Shard, count( b.chunk_number) Number_of_Chunks from 2 gsmadmin_internal.database a, gsmadmin_internal.chunk_loc b where 3 a.database_num=b.database_num group by a.name; SHARD NUMBER_OF_CHUNKS ------------------------------ ---------------- sh1 6 sh2 6 SQL> 另外,re-shard的状态也可以如下检查,可以看到ongoing是空,即在deploy之前,没有re-shard的动作: [oracle12c@sdb1 ~]$ gdsctl config chunks -show_Reshard Chunks ------------------------ Database From To -------- ---- -- sh1 1 6 sh2 7 12 Ongoing chunk movement ------------------------ Chunk Source Target status ----- ------ ------ ------ [oracle12c@sdb1 ~]$ |
5.运行deploy
注意deploy之前,确认新主机上的listener已经被关闭,不然的话,在deploy会报错:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
--如果不关闭listener,会报错。 GDSCTL>deploy GSM Errors: CATALOG:ORA-02610: Remote job failed with error: EXTERNAL_LOG_ID="job_76954_8", USERNAME="oracle12c" For more details: select destination, output from all_scheduler_job_run_details where job_name='SHARD_SH21_NETCA' CATALOG:ORA-45575: Deployment has terminated due to previous errors. --正常的安装,如下: GDSCTL>deploy deploy: examining configuration... deploy: deploying primary shard 'sh21' ... deploy: network listener configuration successful at destination 'sdb4' deploy: starting DBCA at destination 'sdb4' to create primary shard 'sh21' ... deploy: waiting for 1 DBCA primary creation job(s) to complete... deploy: waiting for 1 DBCA primary creation job(s) to complete... deploy: waiting for 1 DBCA primary creation job(s) to complete... deploy: waiting for 1 DBCA primary creation job(s) to complete... deploy: waiting for 1 DBCA primary creation job(s) to complete... deploy: waiting for 1 DBCA primary creation job(s) to complete... deploy: waiting for 1 DBCA primary creation job(s) to complete... deploy: waiting for 1 DBCA primary creation job(s) to complete... deploy: waiting for 1 DBCA primary creation job(s) to complete... deploy: waiting for 1 DBCA primary creation job(s) to complete... deploy: waiting for 1 DBCA primary creation job(s) to complete... deploy: waiting for 1 DBCA primary creation job(s) to complete... deploy: waiting for 1 DBCA primary creation job(s) to complete... deploy: DBCA primary creation job succeeded at destination 'sdb4' for shard 'sh21' deploy: requesting Data Guard configuration on shards via GSM deploy: shards configured; background operations in progress The operation completed successfully GDSCTL> |
在deploy的过程中,可以看re-shard已经在schedule了,注意此时的情况是sdb4正在create instance的过程中:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
[oracle12c@sdb1 ~]$ gdsctl config chunks -show_Reshard Chunks ------------------------ Database From To -------- ---- -- sh1 1 6 sh2 7 12 Ongoing chunk movement ------------------------ Chunk Source Target status ----- ------ ------ ------ 6 sh1 scheduled 5 sh1 scheduled 12 sh2 scheduled 11 sh2 scheduled [oracle12c@sdb1 ~]$ |
注意,deploy完,只是sdb4上的数据库创建完成,chunk是还没有挪完的。
|
1 2 3 4 5 6 7 |
[oracle12c@sdb1 ~]$ gdsctl config shard Name Shard Group Status State Region Availability ---- ----------- ------ ----- ------ ------------ sh1 primary_shardgroup Ok Deployed region1 ONLINE sh2 primary_shardgroup Ok Deployed region1 ONLINE sh21 primary_shardgroup Ok Deployed region1 ONLINE |
6. 观察re-shard的过程,注意Ongoing chunk movement部分的变化:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 |
[oracle12c@sdb1 ~]$ gdsctl config chunks -show_reshard Chunks ------------------------ Database From To -------- ---- -- sh1 1 6 sh2 7 12 Ongoing chunk movement ------------------------ Chunk Source Target status ----- ------ ------ ------ 6 sh1 sh21 scheduled 5 sh1 sh21 scheduled 12 sh2 sh21 scheduled 11 sh2 sh21 scheduled (过一会观察) [oracle12c@sdb1 ~]$ gdsctl config chunks -show_reshard Chunks ------------------------ Database From To -------- ---- -- sh1 1 6 sh2 7 12 Ongoing chunk movement ------------------------ Chunk Source Target status ----- ------ ------ ------ 6 sh1 sh21 copied 5 sh1 sh21 scheduled 12 sh2 sh21 scheduled 11 sh2 sh21 scheduled (过一会观察) [oracle12c@sdb1 ~]$ gdsctl config chunks -show_reshard Chunks ------------------------ Database From To -------- ---- -- sh1 1 5 sh2 7 12 sh21 6 6 Ongoing chunk movement ------------------------ Chunk Source Target status ----- ------ ------ ------ 5 sh1 sh21 started 12 sh2 sh21 scheduled 11 sh2 sh21 scheduled (过一会观察) [oracle12c@sdb1 ~]$ gdsctl config chunks -show_reshard Chunks ------------------------ Database From To -------- ---- -- sh1 1 4 sh2 7 12 sh21 5 6 Ongoing chunk movement ------------------------ Chunk Source Target status ----- ------ ------ ------ 12 sh2 sh21 started 11 sh2 sh21 scheduled (过一会观察) [oracle12c@sdb1 ~]$ gdsctl config chunks -show_reshard Chunks ------------------------ Database From To -------- ---- -- sh1 1 4 sh2 7 11 sh21 5 6 sh21 12 12 Ongoing chunk movement ------------------------ Chunk Source Target status ----- ------ ------ ------ 11 sh2 sh21 started (过一会观察) [oracle12c@sdb1 ~]$ gdsctl config chunks -show_reshard Chunks ------------------------ Database From To -------- ---- -- sh1 1 4 sh2 7 10 sh21 5 6 sh21 11 12 Ongoing chunk movement ------------------------ Chunk Source Target status ----- ------ ------ ------ |
注:如果deploy完之后一直是schedule状态不动,需要config shared看看是否有DDL error。
另外,需要额外提起的是,chunk migration不仅仅是在shard数量发生改变的时候,也发生在数据或者负载倾斜较大的时候(是由DBA发起)。在chunk migration的时候,chunk大部分时间是online的,但是期间会有几秒钟的时间chunk中的data处于read-only状态。
我们来手工的move一下chunk:
|
1 2 3 |
GDSCTL>MOVE CHUNK -CHUNK 4 -SOURCE sh1 -TARGET sh21 The operation completed successfully GDSCTL> |
另一窗口:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
[oracle12c@sdb1 ~]$ gdsctl config chunks -show_reshard Chunks ------------------------ Database From To -------- ---- -- sh1 1 4 sh2 7 10 sh21 5 6 sh21 11 12 Ongoing chunk movement ------------------------ Chunk Source Target status ----- ------ ------ ------ 4 sh1 sh21 started (过一会观察) [oracle12c@sdb1 ~]$ gdsctl config chunks -show_reshard Chunks ------------------------ Database From To -------- ---- -- sh1 1 3 sh2 7 10 sh21 4 6 sh21 11 12 Ongoing chunk movement ------------------------ Chunk Source Target status ----- ------ ------ ------ |
做move shard,我们来看看对应的节点的alertlog:
节点sh1的alertlog:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
2016-11-10T17:38:13.430097+08:00 alter tablespace "C004TSP_SET_1" READ ONLY 2016-11-10T17:38:13.462870+08:00 Converting block 0 to version 10 format Completed: alter tablespace "C004TSP_SET_1" READ ONLY 2016-11-10T17:38:15.202020+08:00 DM00 started with pid=60, OS id=6099, job GSMADMIN_INTERNAL.SYS_EXPORT_TRANSPORTABLE_01 2016-11-10T17:38:16.688903+08:00 DW00 started with pid=61, OS id=6101, wid=1, job GSMADMIN_INTERNAL.SYS_EXPORT_TRANSPORTABLE_01 2016-11-10T17:39:03.939903+08:00 Some indexes or index [sub]partitions of table APP_SCHEMA.LINEITEMS have been marked unusable 2016-11-10T17:39:04.578624+08:00 Some indexes or index [sub]partitions of table APP_SCHEMA.ORDERS have been marked unusable 2016-11-10T17:39:04.678710+08:00 Some indexes or index [sub]partitions of table APP_SCHEMA.CUSTOMERS have been marked unusable drop tablespace "C004TSP_SET_1" including contents 2016-11-10T17:39:06.693499+08:00 Deleted Oracle managed file /u01/ora12c/app/oracle/oradata/SH1/datafile/o1_mf_c004tsp__d28dcj4w_.dbf Completed: drop tablespace "C004TSP_SET_1" including contents 2016-11-10T17:44:10.282821+08:00 Starting control autobackup Control autobackup written to DISK device handle '/u01/ora12c/app/oracle/fast_recovery_area/SH1/autobackup/2016_11_10/o1_mf_s_927567850_d28jcbo5_.bkp' |
节点sh21的alertlog:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
2016-11-10T17:39:37.392725+08:00 Full restore complete of datafile 10 to datafile copy /u01/ora12c/app/oracle/oradata/SH21/datafile/o1_mf_c004tsp__d28dcj4w_.dbf. Elapsed time: 0:00:00 checkpoint is 1471673 last deallocation scn is 1431063 2016-11-10T17:40:13.636724+08:00 Incremental restore complete of datafile 10 to datafile copy /u01/ora12c/app/oracle/oradata/SH21/datafile/o1_mf_c004tsp__d28dcj4w_.dbf checkpoint is 1471679 last deallocation scn is 1431063 2016-11-10T17:40:14.957209+08:00 DM00 started with pid=54, OS id=5456, job GSMADMIN_INTERNAL.SYS_IMPORT_TRANSPORTABLE_01 2016-11-10T17:40:15.530391+08:00 DW00 started with pid=55, OS id=5458, wid=1, job GSMADMIN_INTERNAL.SYS_IMPORT_TRANSPORTABLE_01 2016-11-10T17:40:18.143905+08:00 Plug in tablespace C004TSP_SET_1 with datafile '/u01/ora12c/app/oracle/oradata/SH21/datafile/o1_mf_c004tsp__d28dcj4w_.dbf' 2016-11-10T17:40:20.382693+08:00 ALTER TABLESPACE "C004TSP_SET_1" READ WRITE Completed: ALTER TABLESPACE "C004TSP_SET_1" READ WRITE ALTER TABLESPACE "C004TSP_SET_1" READ ONLY 2016-11-10T17:40:20.925913+08:00 Converting block 0 to version 10 format Completed: ALTER TABLESPACE "C004TSP_SET_1" READ ONLY 2016-11-10T17:40:24.893850+08:00 alter tablespace "C004TSP_SET_1" read write Completed: alter tablespace "C004TSP_SET_1" read write 2016-11-10T17:49:12.080018+08:00 Starting control autobackup 2016-11-10T17:49:13.293974+08:00 Control autobackup written to DISK device handle '/u01/ora12c/app/oracle/fast_recovery_area/SH21/autobackup/2016_11_10/o1_mf_s_927568152_d28jnrnp_.bkp' |
从上面的alertlog,我们大致的可以看出,chunk migration的过程就是综合利用全备和增备,以及TTS的过程:
level 0备份源chunk相关的TS,还原到新shard->开始FAN(等待几秒)->将源chunk相关的TS置于read-only->level 1备份还原->chunk up(更新routing table连新shard)->chunk down(更新routing table断开源shard)->结束FAN(等待几秒)->删除原shard上的老chunk
最后我们再来看一下remove shard。
remove shard的命令,发起的时候,要求你remove的那个shard,不能有chunk在上面,不然报错:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
GDSCTL>REMOVE SHARD -shard sh21 GSM-45029: SQL error ORA-02659: cannot remove a shard which contains chunks ORA-06512: at "GSMADMIN_INTERNAL.DBMS_GSM_POOLADMIN", line 10699 ORA-06512: at "SYS.DBMS_SYS_ERROR", line 79 ORA-06512: at "GSMADMIN_INTERNAL.DBMS_GSM_POOLADMIN", line 10510 ORA-06512: at "GSMADMIN_INTERNAL.DBMS_GSM_POOLADMIN", line 10310 ORA-06512: at line 1 GDSCTL> GDSCTL> GDSCTL> |
所以我们先movechunk先。将sh21上的chunk移走:
|
1 2 3 4 5 6 |
GDSCTL>move chunk -chunk 4,5,6 -source sh21 -target sh1 The operation completed successfully GDSCTL>move chunk -chunk 8,11,12 -source sh21 -target sh2 The operation completed successfully GDSCTL> GDSCTL> |
注意此时,虽然remove chunk的命令已经执行成功,但是move chunk的动作其实还在后台进行中的。用config chunks命令检查,看到sh21上,还是有chunks在的。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
GDSCTL>config chunks Chunks ------------------------ Database From To -------- ---- -- sh1 1 5 sh2 7 7 sh2 9 10 sh21 6 6 sh21 8 8 sh21 11 12 GDSCTL> GDSCTL> |
我们不断运行show_reshard看其结果。直到Ongoing chunk movement部分为空,说明没有再需要move的chunk了。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 |
GDSCTL>config chunks -show_reshard Chunks ------------------------ Database From To -------- ---- -- sh1 1 5 sh2 7 7 sh2 9 10 sh21 6 6 sh21 8 8 sh21 11 12 Ongoing chunk movement ------------------------ Chunk Source Target status ----- ------ ------ ------ 8 sh21 sh2 scheduled 11 sh21 sh2 scheduled 6 sh21 sh1 started 12 sh21 sh2 scheduled GDSCTL> GDSCTL> GDSCTL>config chunks -show_reshard Chunks ------------------------ Database From To -------- ---- -- sh1 1 6 sh2 7 7 sh2 9 10 sh21 8 8 sh21 11 12 Ongoing chunk movement ------------------------ Chunk Source Target status ----- ------ ------ ------ 8 sh21 sh2 started 11 sh21 sh2 scheduled 12 sh21 sh2 scheduled GDSCTL>config chunks -show_reshard Chunks ------------------------ Database From To -------- ---- -- sh1 1 6 sh2 7 10 sh21 11 12 Ongoing chunk movement ------------------------ Chunk Source Target status ----- ------ ------ ------ 8 sh21 sh2 finished 11 sh21 sh2 scheduled 12 sh21 sh2 scheduled GDSCTL> GDSCTL>config chunks -show_reshard Chunks ------------------------ Database From To -------- ---- -- sh1 1 6 sh2 7 10 sh21 11 12 Ongoing chunk movement ------------------------ Chunk Source Target status ----- ------ ------ ------ 11 sh21 sh2 started 12 sh21 sh2 scheduled GDSCTL>config chunks -show_reshard Chunks ------------------------ Database From To -------- ---- -- sh1 1 6 sh2 7 10 sh21 11 12 Ongoing chunk movement ------------------------ Chunk Source Target status ----- ------ ------ ------ 11 sh21 sh2 started 12 sh21 sh2 scheduled GDSCTL>config chunks -show_reshard Chunks ------------------------ Database From To -------- ---- -- sh1 1 6 sh2 7 12 Ongoing chunk movement ------------------------ Chunk Source Target status ----- ------ ------ ------ GDSCTL> GDSCTL> |
这个时候看config chunks,就只看到所有的chunks在2个shard上了。此时进行remove shard:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
GDSCTL>config chunks Chunks ------------------------ Database From To -------- ---- -- sh1 1 6 sh2 7 12 GDSCTL> GDSCTL> GDSCTL> GDSCTL> GDSCTL> GDSCTL>REMOVE SHARD -shard sh21 The operation completed successfully GDSCTL> GDSCTL> GDSCTL>config Regions ------------------------ region1 GSMs ------------------------ sharddirector1 Sharded Database ------------------------ shardcat Databases ------------------------ sh1 sh2 Shard Groups ------------------------ primary_shardgroup Shard spaces ------------------------ shardspaceora Services ------------------------ oltp_rw_srvc GDSCTL pending requests ------------------------ Command Object Status ------- ------ ------ Global properties ------------------------ Name: oradbcloud Master GSM: sharddirector1 DDL sequence #: 14 GDSCTL>config shard Name Shard Group Status State Region Availability ---- ----------- ------ ----- ------ ------------ sh1 primary_shardgroup Ok Deployed region1 ONLINE sh2 primary_shardgroup Ok Deployed region1 ONLINE GDSCTL> |
注意此时,在sdb4上的sh21的实例,还是存在的,这个实例需要手工删除。remove shard命令不会帮你删除sh21实例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 |
[oracle12c@sdb4 ~]$ rman target / Recovery Manager: Release 12.2.0.1.0 - Production on Thu Nov 10 23:07:03 2016 Copyright (c) 1982, 2016, Oracle and/or its affiliates. All rights reserved. connected to target database: SH21 (DBID=2230460441) RMAN> STARTUP FORCE MOUNT Oracle instance started database mounted Total System Global Area 1027604480 bytes Fixed Size 8628400 bytes Variable Size 742393680 bytes Database Buffers 272629760 bytes Redo Buffers 3952640 bytes RMAN> SQL 'ALTER SYSTEM ENABLE RESTRICTED SESSION'; using target database control file instead of recovery catalog sql statement: ALTER SYSTEM ENABLE RESTRICTED SESSION RMAN> DROP DATABASE INCLUDING BACKUPS NOPROMPT; database name is "SH21" and DBID is 2230460441 allocated channel: ORA_DISK_1 channel ORA_DISK_1: SID=39 device type=DISK List of Backup Pieces BP Key BS Key Pc# Cp# Status Device Type Piece Name ------- ------- --- --- ----------- ----------- ---------- 1 1 1 1 AVAILABLE DISK /u01/ora12c/app/oracle/fast_recovery_area/SH21/autobackup/2016_11_10/o1_mf_s_927566646_d28h5qhh_.bkp 2 2 1 1 AVAILABLE DISK /u01/ora12c/app/oracle/fast_recovery_area/SH21/autobackup/2016_11_10/o1_mf_s_927568152_d28jnrnp_.bkp 3 3 1 1 AVAILABLE DISK /u01/ora12c/app/oracle/fast_recovery_area/SH21/autobackup/2016_11_10/o1_mf_s_927586883_d292y46h_.bkp deleted backup piece backup piece handle=/u01/ora12c/app/oracle/fast_recovery_area/SH21/autobackup/2016_11_10/o1_mf_s_927566646_d28h5qhh_.bkp RECID=1 STAMP=927566647 deleted backup piece backup piece handle=/u01/ora12c/app/oracle/fast_recovery_area/SH21/autobackup/2016_11_10/o1_mf_s_927568152_d28jnrnp_.bkp RECID=2 STAMP=927568152 deleted backup piece backup piece handle=/u01/ora12c/app/oracle/fast_recovery_area/SH21/autobackup/2016_11_10/o1_mf_s_927586883_d292y46h_.bkp RECID=3 STAMP=927586884 Deleted 3 objects released channel: ORA_DISK_1 allocated channel: ORA_DISK_1 channel ORA_DISK_1: SID=39 device type=DISK specification does not match any datafile copy in the repository specification does not match any control file copy in the repository specification does not match any control file copy in the repository List of Archived Log Copies for database with db_unique_name SH21 ===================================================================== Key Thrd Seq S Low Time ------- ---- ------- - --------- 1 1 1 A 10-NOV-16 Name: /u01/ora12c/app/oracle/fast_recovery_area/SH21/archivelog/2016_11_10/o1_mf_1_1_d28yvcxv_.arc deleted archived log archived log file name=/u01/ora12c/app/oracle/fast_recovery_area/SH21/archivelog/2016_11_10/o1_mf_1_1_d28yvcxv_.arc RECID=1 STAMP=927582808 Deleted 1 objects database name is "SH21" and DBID is 2230460441 database dropped RMAN> RMAN>exit Recovery Manager complete. [oracle12c@sdb4 ~]$ [oracle12c@sdb4 ~]$ lsnrctl stop LISTENER_SH21 LSNRCTL for Linux: Version 12.2.0.1.0 - Production on 10-NOV-2016 23:09:00 Copyright (c) 1991, 2016, Oracle. All rights reserved. Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=sdb4)(PORT=1521))) The command completed successfully [oracle12c@sdb4 ~]$ |