alwayson数据同步流程图(以SAP应用为例):
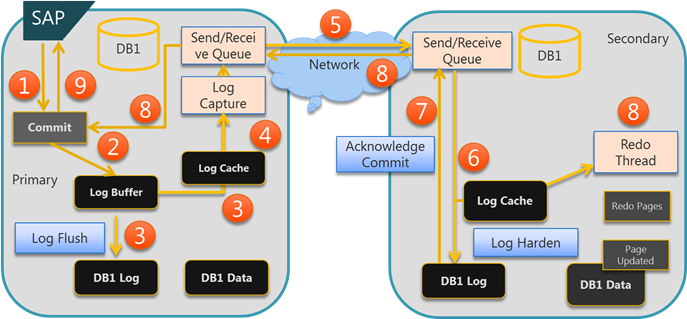
上图中:
Step 1: In a typical case the SAP application would send a commit to finalize a transaction.
Step 2: The commit record is inserted into the actual log buffer.
Step 3: The commit record triggers a flush of the log buffer to persist the buffer in the transaction log on the instance running the primary replica. In the same notion the buffer is copied into the new log cache. If all secondary replicas are in an asynchronous availability mode, the success of this step would be good enough to send an acknowledge message of a successful commit back to the application when the I/O to the local transaction log successfully executed.
Step 4: The new log capture framework will now capture the new log data and will hand it over into our messaging framework which will manage the send and receive queues as well as failure detection in the network traffic.
Step 5: The change records as persisted to the transaction log of the primary are getting transferred to the instances in the secondary role. The log content is getting compressed and encrypted before sending it over the instances running the secondary replicas.
Step 6: The content received from the messaging framework gets persisted in the transaction log of the secondary replicas and at the same time get inserted into the log cache of the secondary replicas.
Step 7: The moment the content was successfully persisted in the transaction log of the secondary instance an acknowledge message is sent to the messaging framework.
Step 8: As the acknowledge messages of the successful persist on the secondary replica is sent to the primary replica, the secondary replica is starting to apply the changes to the actual data pages. If all the acknowledges of the synchronous secondary replicas is received on the instance running the primary replica the next step can be done.
Step 9: The acknowledge message is sent to the SAP application.
所以,如果是async异步的话,到第三步就结束了。同步的话,还要经历后面的第四步~第九步。
也就是说,如果是异步,也就还要加上通过网络传输,从主库的send queue到备库receive queue,再将信息写入备库的log cache,再将log cache持久化(harden)到transaction log,在从备库返回该确认信息到send queue,再从queue通过网络到主库。
我们现在来看看当前系统RTO和RPO的计算。
(一)RTO的计算:
RTO指故障转移时间,是指在发生灾难的时候,多长时间能切换到灾备库。
在MSSQL中,RTO的计算公式是:
|
1 |
T_failover=T_detection+T_redo+T_overhead |
其中:
T_detection是指alwayson发送错误给WSFC的时间,默认值为0,或者集群健康检查超时sp_server_diagnostics存储过程(默认30秒)或者resource DLL和SQL Server实例的租用超时(默认20秒)
T_redo=redo_queue/redo_rate。其中redo_queue可以从sys.dm_hadr_database_replica_states的redo_queue_size获得,单位KB;redo_rate可以从sys.dm_hadr_database_replica_states的redo_queue_size的redo_rate获得,单位kb/sec.
T_overhead的时间,包括它采用故障转移 WSFC 群集,以及若要使数据库联机的时间。 此时间通常是短期和常量。
注:sys.dm_hadr_database_replica_states这个动态性能视图,在辅助副本上,此视图为服务器实例上的每个辅助数据库都返回一行。 在主副本上,此视图为每个主数据库都返回一行,并且为相应的辅助数据库另外返回一行。
举个例子:
|
1 2 |
select redo_rate,redo_queue_size from sys.dm_hadr_database_replica_states; --11484 55 |
那么T_redo=55/11484=0.00478927 sec = 4.8ms
假设故障转移使得数据库重新联机为60秒。
那么RTO的时间为30+0.0048+60=90.0048秒。
(二)RPO的计算:
RPO指灾难发生的时候,可能丢失的数据量。
在MSSQL中,RPO的计算公式是:
|
1 |
T_data_loss=log_send_queue/log generation rate |
其中:
log_send_queue可以通过sys.dm_hadr_database_replica_states中的log_send_queue_size获得。注意单位是KB。
log generation rate可以通过sys.dm_os_performance_counters中的counter_name like ‘Log Bytes Flushed/sec%’获得,注意单位是Bytes每秒。
举个例子:
|
1 2 3 4 5 6 7 |
select log_send_queue_size from sys.dm_hadr_database_replica_states; --60 KB select SYSDATETIME() as 'chktime',counter_name,cntr_value FROM sys.dm_os_performance_counters where counter_name like 'Log Bytes Flushed/sec%' and instance_name='MyDB001_KSH' --2017-03-21 15:46:11.8513659 Log Bytes Flushed/sec 21535397888 --2017-03-21 15:46:29.0862228 Log Bytes Flushed/sec 21541011968 --delta: 311893/sec -- 311KB/sec |
所以RPO的值就是60/311=0.19 sec,也就是说,在当时如果发生灾难,将丢失0.19秒的日志数据。
另外,还可以简单的通过使用last_commit_time来评估 T_data_loss(这也是微软官方的说法)
priamry会把这个值发给所有的secondary,可以计算primary副本和secondary 副本的值的差,来评估需要多久secondary副本可以追上primary副本。虽然不能准确的表示数据丢失,但是已经很接近了。
主数据库上,这对应于上次处理的提交记录。 辅助数据库的行显示辅助副本已发送到主副本的日志序列号。
在辅助副本上,这是已重做的最后一个提交记录。
|
1 2 3 4 5 6 |
--在主库查: select last_commit_time as 'primary_last_commit_tm' from sys.dm_hadr_database_replica_states where is_local=1; select last_commit_time as 'standby_last_commit_tm' from sys.dm_hadr_database_replica_states where is_local=0; -- primary:2017-03-21 15:31:37.930 -- standby:2017-03-21 15:31:38.377 --delta:0.447 sec |
综上,作为监控指标,可以将上述的last_commit_time,作为主备之间的lag作为计算标准。我们可以假设,当lag之间的差距超过30分钟,可以作为需要DBA介入的标准。
参考:
Monitor Performance for AlwaysOn Availability Groups
The AlwaysOn Health Model Part 2 — Extending the Health Model
DatabaseReplicaState Class
sys.dm_hadr_database_replica_states (Transact-SQL)
Running SAP Applications on the Microsoft Platform