很久以前,我写过一个文章,《如何查找疯狂增长arch的进程》,讲述在oracle数据库中如何查找导致当前疯狂增长arch的session。今天,我们在postgresql数据库中也遇到了类似的问题。
在一个时间内,wal日志疯狂的增长,大约每分钟产生1G,而xlog疯狂cp去归档的结果,导致xlog来不及流复制到从库就已经切去了归档目录,进而导致了主从断开。
和开发一起诊断了这个问题之后,发现是一个update语句更新了大量的记录,每次更新1000多万记录中的200多万,这个表上14个字段中10个字段有有索引。更新时是非HOT update。这个语句每小时跑一次,每次跑的时候,有12个类似的语句。开发修改语句之后,增加了where的过滤条件后,减少了更新的数据量,从200多万减少了几行,从而解决了这个问题。
事后,我一直在想,如果没有开发人员,我们dba是否也可以从数据库本身的信息中发现问题?找到语句? 在一次偶然的机会中,和平安科技的梁海安聊天时中得到了答案。
在oracle中导致归档过多的,是过于频繁的dml语句。在pg中也是一样。只是在oracle中有v$sesstat中可以看到redo size的信息,而在pg的pg_stat_activity中只有session的信息,并没有语句的wal信息。但是由于wal的产生也是因为过多的dml引起的,我们可以从pg_catalog.pg_stat_all_tables中去找变动频繁的tuple(n_tup_ins,n_tup_upd,n_tup_del,主要是update),从而发现导致dml过多的语句。
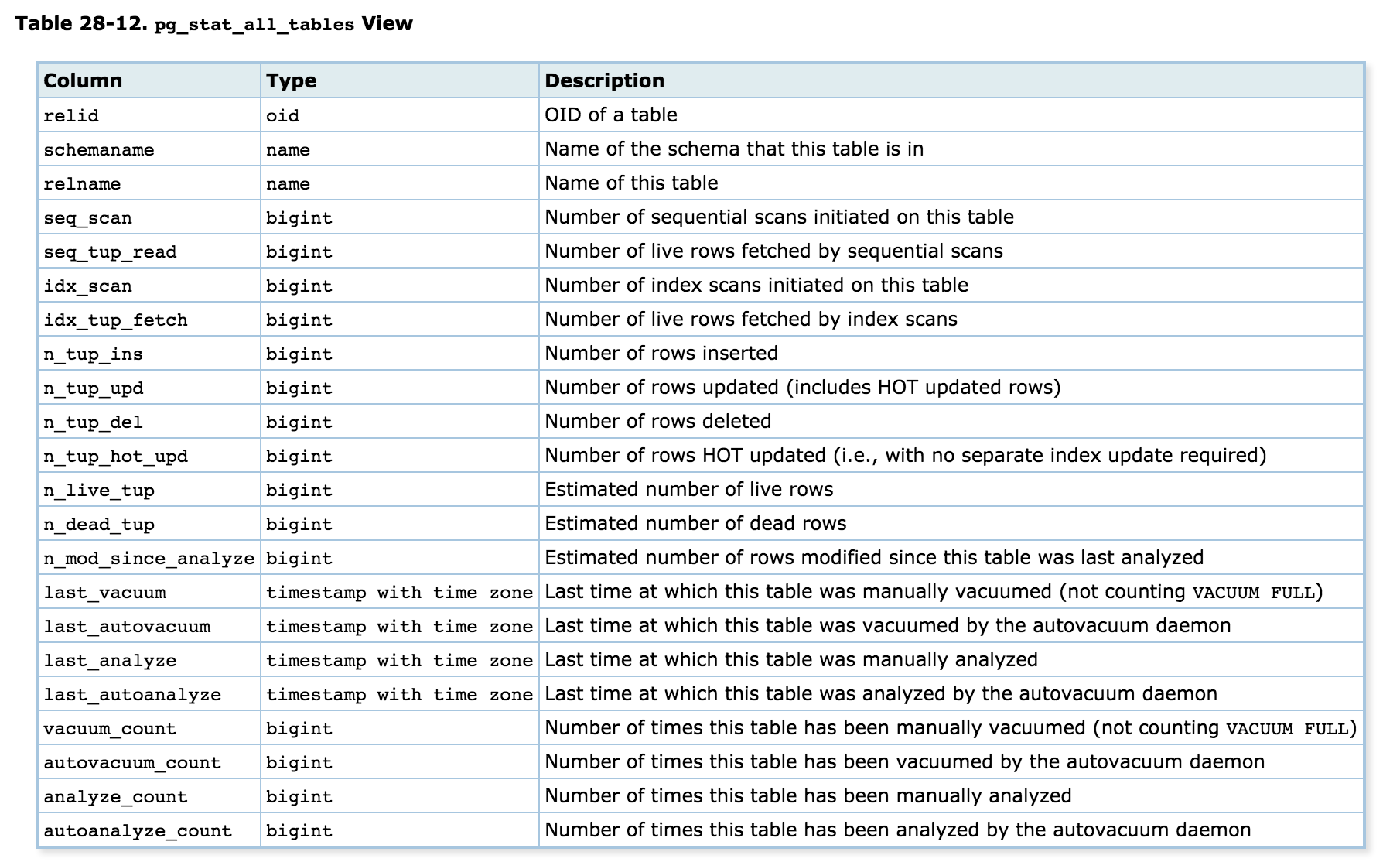
解决方法如下:
1. 开启pg的dml审计。在postgresql.conf中设置log_statement=’mod’
2. 截取一个时间的pg_catalog.pg_stat_all_tables:
|
1 2 |
create table orasup1 as select date_trunc('second',now()) as sample_time,schemaname,relname,n_tup_ins,n_tup_upd,n_tup_del,n_tup_hot_upd from pg_catalog.pg_stat_all_tables; |
3. 截取另外一个时间的pg_catalog.pg_stat_all_tables:
|
1 2 |
create table orasup2 as select date_trunc('second',now()) as sample_time,schemaname,relname,n_tup_ins,n_tup_upd,n_tup_del,n_tup_hot_upd from pg_catalog.pg_stat_all_tables; |
4. 检查在单位时间内,那个对象的dml最多:
|
1 2 3 4 5 6 7 8 9 10 11 |
select t2.schemaname,t2.relname, (t2.n_tup_ins-t1.n_tup_ins) as delta_ins, (t2.n_tup_upd-t1.n_tup_upd) as delta_upd, (t2.n_tup_del-t1.n_tup_del) as delta_del, (t2.n_tup_ins+t2.n_tup_upd+t2.n_tup_del-t1.n_tup_ins-t1.n_tup_upd-t1.n_tup_del) as del_dml, (EXTRACT (EPOCH FROM t2.sample_time::timestamp )::float-EXTRACT (EPOCH FROM t1.sample_time::timestamp )::float) as delta_second, round(cast((t2.n_tup_ins+t2.n_tup_upd+t2.n_tup_del-t1.n_tup_ins-t1.n_tup_upd-t1.n_tup_del)/(EXTRACT (EPOCH FROM t2.sample_time::timestamp )::float-EXTRACT (EPOCH FROM t1.sample_time::timestamp )::float)as numeric),2) as delta_dml_per_sec from orasup2 t2, orasup1 t1 where t2.schemaname=t1.schemaname and t2.relname=t1.relname order by delta_dml_per_sec desc limit 10; platform=# |
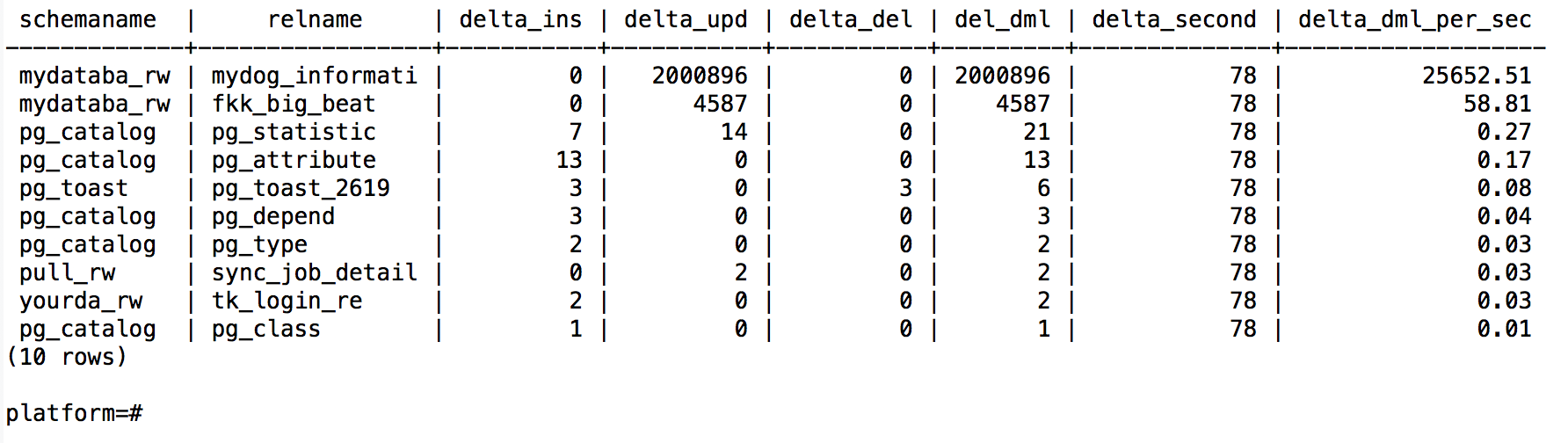
6. 此时我们已经得到了dml最多的对象,结合第1步的审计,就可以找到对应的语句了。
7. 清理战场,drop table orasup1; drop table orasup2;并且恢复审计粒度为log_statement=ddl