在一次对线上系统的压测过程中,数据库突然变成了只读状态。我们看了一下,是因为空间在短时间内,被撑爆了。云上的rds数据库,如果在空间打爆的情况下,确实会变成只读的情况。
我们这个业务,做了中美数据拆分,美国的数据库是在aws上,中国的数据库是在阿里云上,跑同样的一套逻辑。
可以看到,在短时间内:
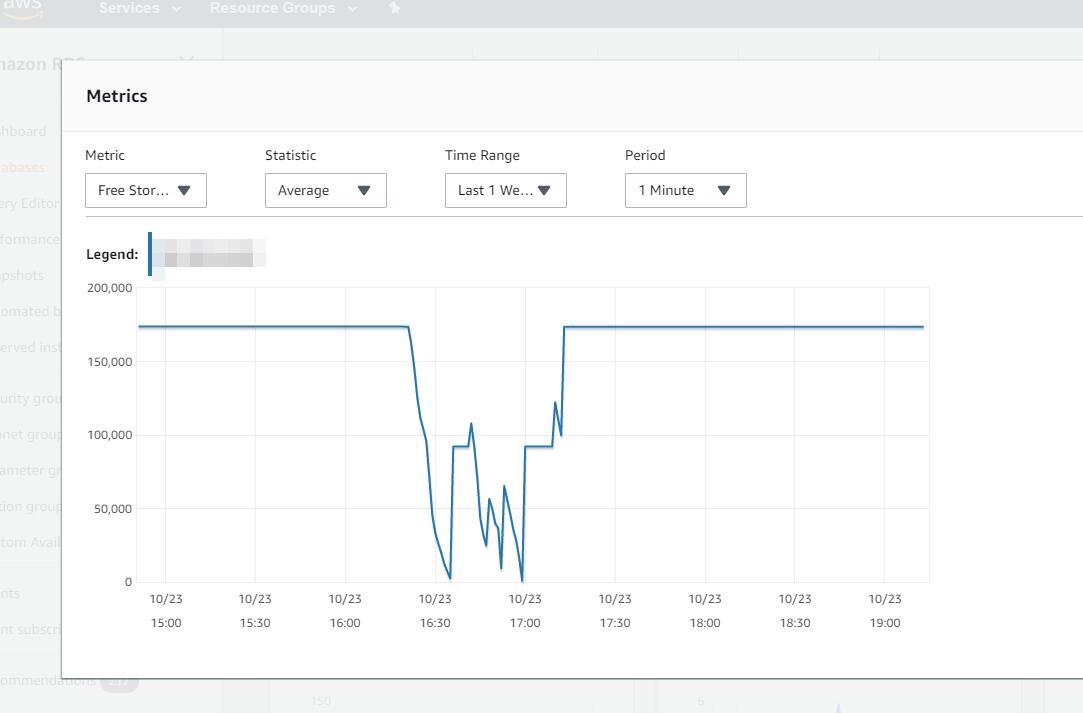
aws云:
阿里云:
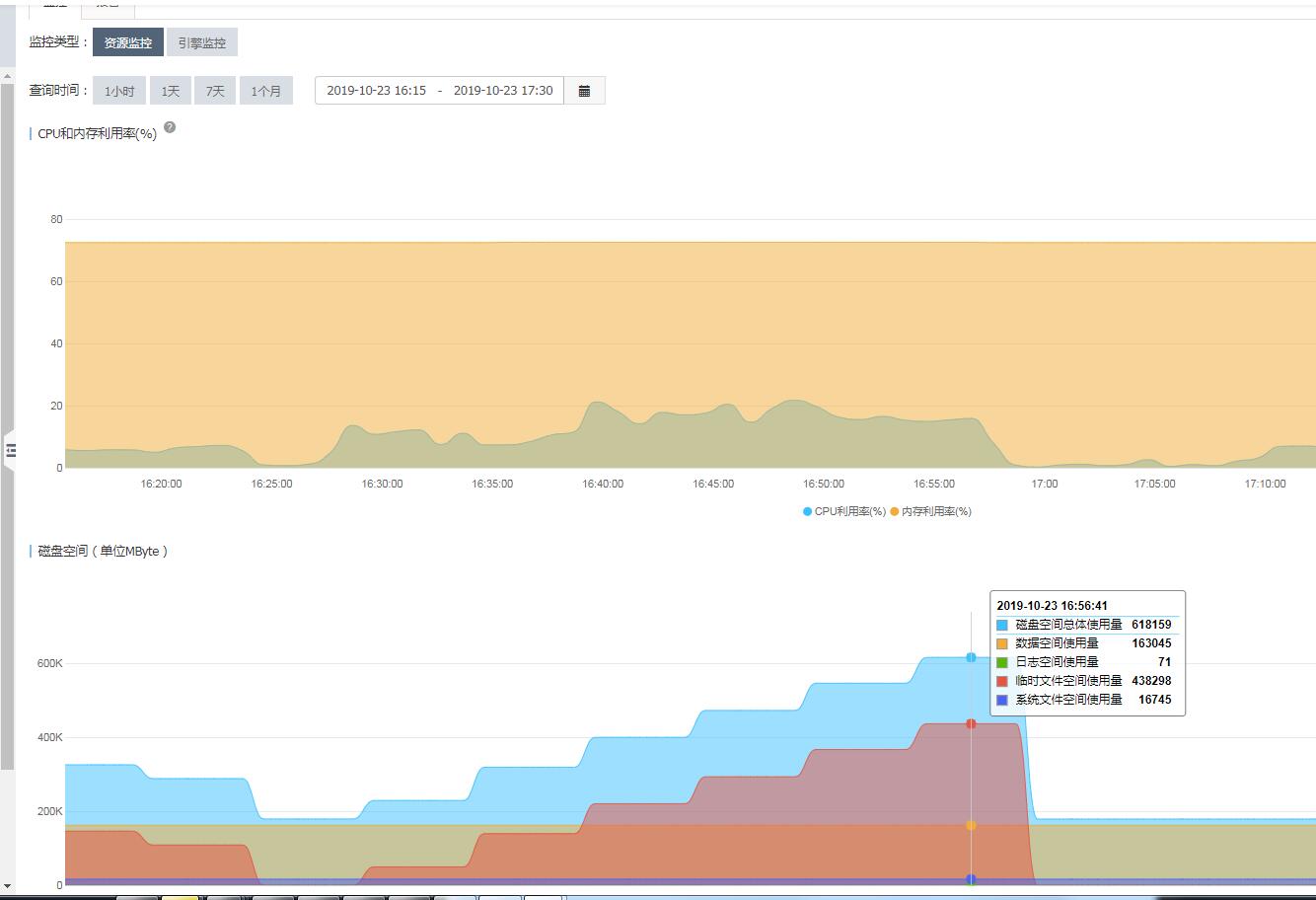
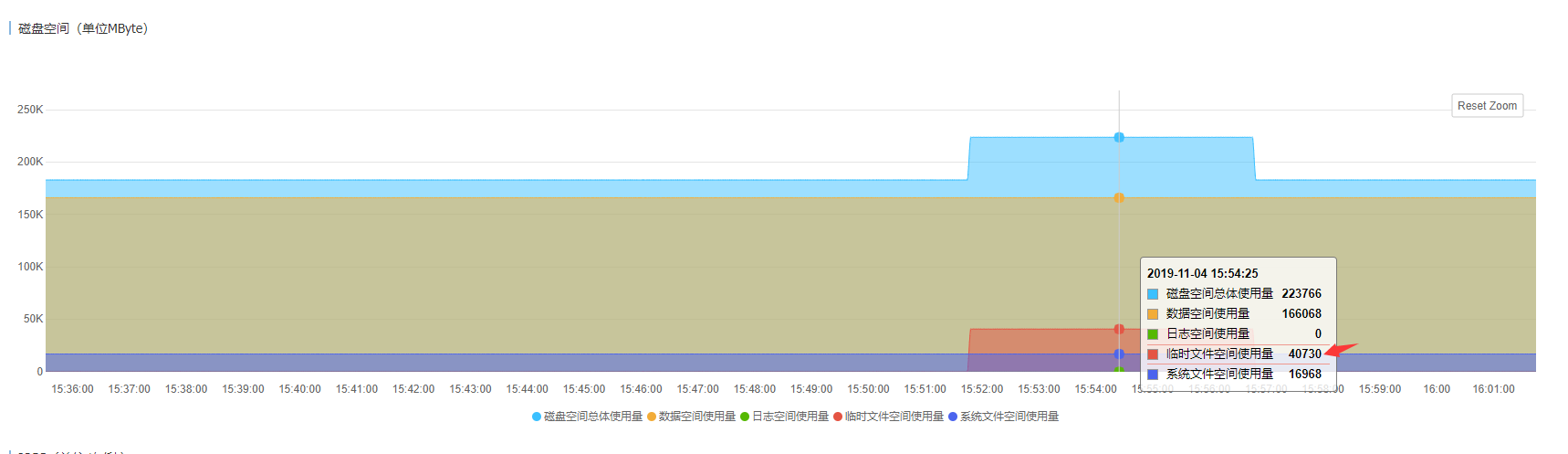
aws的free storage 迅速下降,最低的时候,只有10多G;而阿里云,已经被打爆,阿里云上的空间阈值是500G,故障的时候,已经突发到了600G,其中主要的占据部分,是红色的部分,也就是临时文件的大小。
因此,综上,可以看的,在十几分钟内,数据库的空间就被占据了200G到400G不等。一方面,说明数据库的IO能力确实还不错。另外一方面,数据库确实存在了异常。我们需要找到是什么原因导致了空间迅速被消耗的原因。
在顺便这里说一下aws和和阿里云的监控,可以看的阿里云的空间监控,比aws的信息更加详细,因为aws只有一个free storage的值,而阿里云中,可以看的存储空间猛增的原因,是其中红色部分的临时文件的空间猛增。这为我们后续的分析,提供了很重要的信息。如果光是从aws的监控,我们下手会增加一定的难度。
我们在当时登录到了aws的rds里面,没有看到insert语句,看到有几个select语句,当时是处于creating sort index,从跑的时间看,一些线程已经跑了700多秒,一些线程跑了200多秒。显然,跑的都不快。虽然值得怀疑,当时感觉不应该会消耗那么高的临时空间。但是但是确实没有其他异常的语句,和开发确认后,kill掉了creating sort index的语句。空间立马就恢复回去了。
看来引发问题的语句是确认了。接下来需要分析,这个语句为什么会消耗这么多临时空间。因为根据经验,一个排序的语句,一般消耗4,5百M的临时段,也是顶天了。为什么这个语句会消耗那么多的临时空间呢?
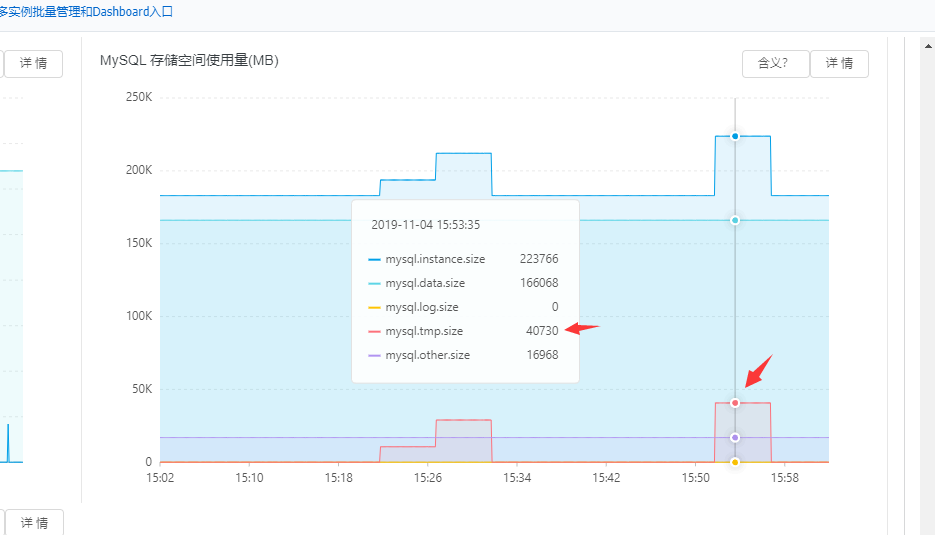
在阿里云中有个CloudDBA,我们可以看到更多的一些信息来辅助分析。
比如这个“性能趋势”
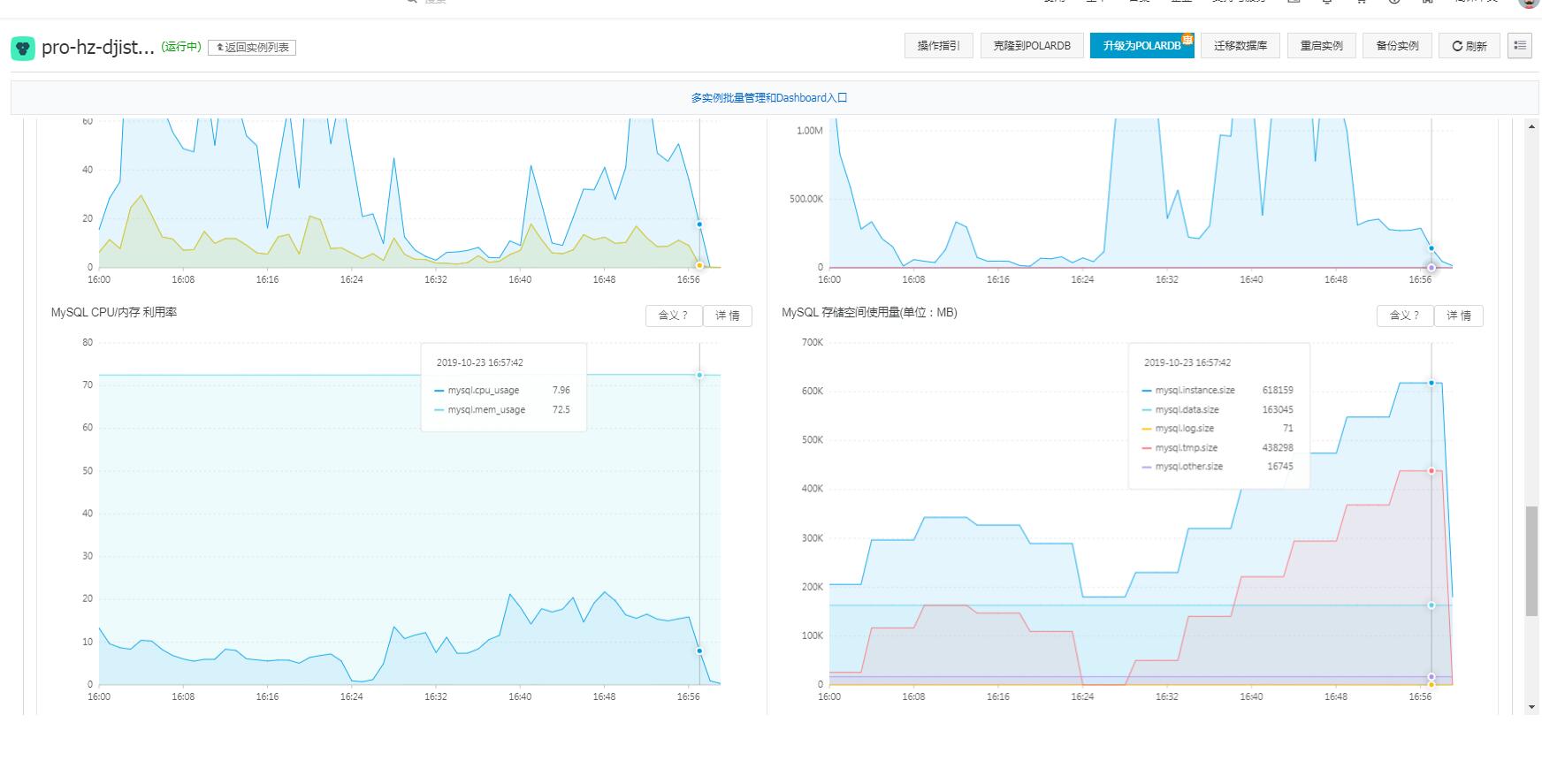
可以看到精确的消耗临时文件的值,为438298M。
另外有个“性能洞察”
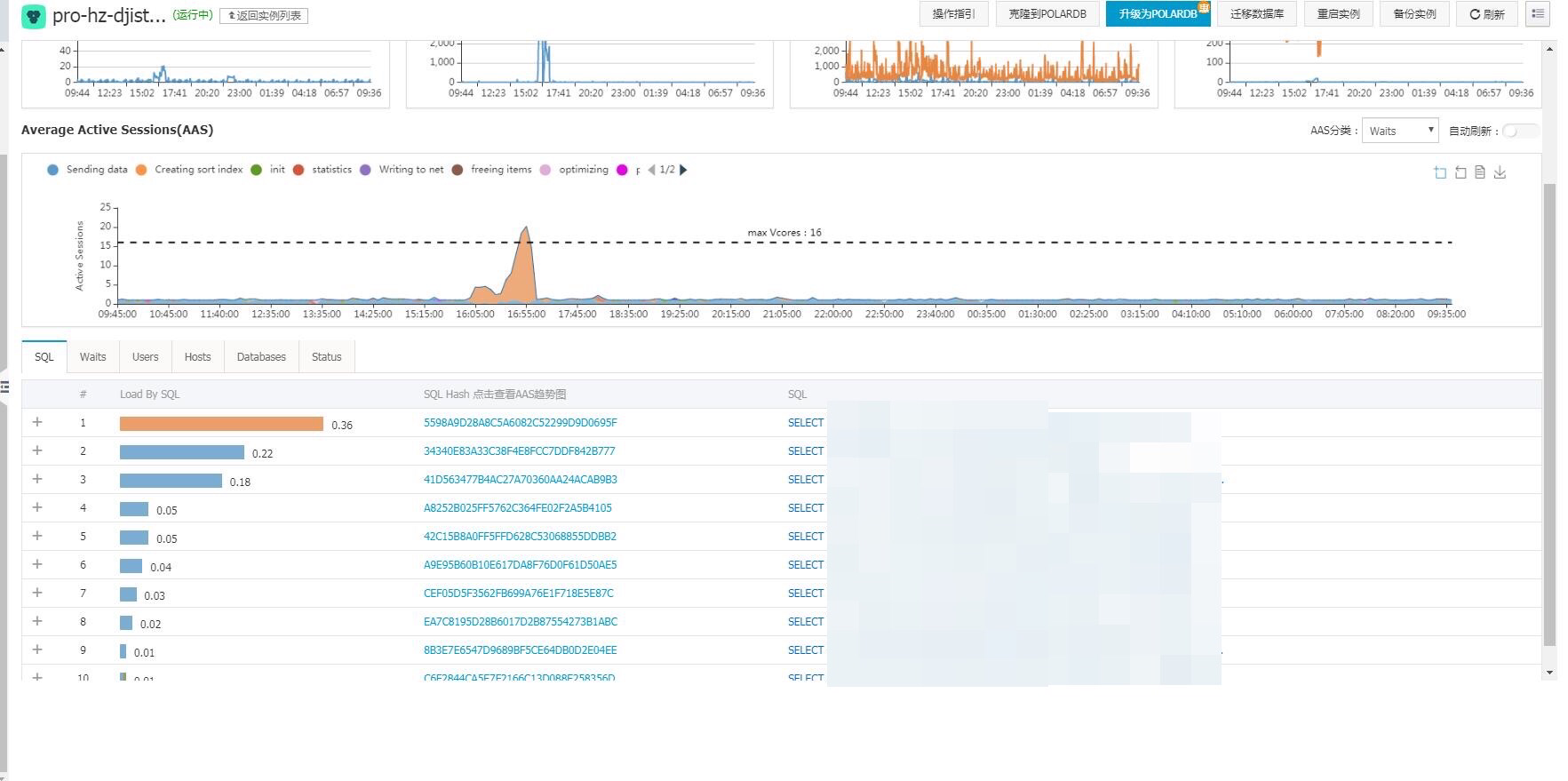
可以看到,当时约有16个active session,是消耗在橙色的creating sort index,并且可以看到绑定变量之后的sql语句。
|
1 2 3 4 5 6 |
SELECT `myabccydf_table`.* FROM `myabccydf_table` INNER JOIN `ownddeu_mynameac` ON `ownddeu_mynameac`.`id` = `myabccydf_table`.`item_id` WHERE `ownddeu_mynameac`.`published_at` <= NOW() + INTERVAL ? DAY ORDER BY `myabccydf_table`.`updated_at` DESC LIMIT ?, ? |
当时这个sql语句有使用绑定变量,这边显示了?,我们需要更精确的定位到语句。我们可以从多个地方去找到这个具体的sql。一个是通过慢查询记录的语句,因为这些语句基本需要执行几百秒的时间。一个是我们DBA团队部署的myawr,它会定期的把show processlist的结果打快照下来。另外,我们还可以通过登录aws时候抓到的语句来去看,因为两边的逻辑是一样的,是一套程序跑2个云。所以我们最终抓到了语句是:
|
1 2 3 4 |
SELECT `myabccydf_table`.* FROM `myabccydf_table` INNER JOIN `ownddeu_mynameac` ON `ownddeu_mynameac`.`id` = `myabccydf_table`.`item_id` WHERE (`ownddeu_mynameac`.`published_at` <= NOW() + INTERVAL 0 DAY) ORDER BY `myabccydf_table`.`updated_at` desc LIMIT 10 OFFSET 0 |
这个语句,分析了一下执行计划,如下:
|
1 2 3 4 5 6 7 8 9 10 11 |
mysql> explain SELECT `myabccydf_table`.* FROM `myabccydf_table` -> INNER JOIN `ownddeu_mynameac` ON `ownddeu_mynameac`.`id` = `myabccydf_table`.`item_id` -> WHERE (`ownddeu_mynameac`.`published_at` <= NOW() + INTERVAL 0 DAY) -> ORDER BY `myabccydf_table`.`updated_at` desc LIMIT 10 OFFSET 0; +----+-------------+------------------+--------+---------------+---------+---------+----------------------------------------------+----------+-----------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+------------------+--------+---------------+---------+---------+----------------------------------------------+----------+-----------------------------+ | 1 | SIMPLE | myabccydf_table | ALL | NULL | NULL | NULL | NULL | 26875439 | Using where; Using filesort | | 1 | SIMPLE | ownddeu_mynameac | eq_ref | PRIMARY | PRIMARY | 4 | dji_store_production.myabccydf_table.item_id | 1 | Using where | +----+-------------+------------------+--------+---------------+---------+---------+----------------------------------------------+----------+-----------------------------+ 2 rows in set (0.01 sec) |
检查了一下这个sql语句返回的函数,也就2000多万行:
|
1 2 3 4 5 6 7 8 9 |
mysql> SELECT count(*) FROM `myabccydf_table` -> INNER JOIN `ownddeu_mynameac` ON `ownddeu_mynameac`.`id` = `myabccydf_table`.`item_id` -> WHERE (`ownddeu_mynameac`.`published_at` <= NOW() + INTERVAL 0 DAY); +----------+ | count(*) | +----------+ | 26385116 | +----------+ 1 row in set (30.85 sec) |
感觉千万级的记录有order by排序,虽然排序字段上没有索引,但是也不应该消耗那么多临时空间用来排序。
看到语句是个select *,直觉上觉得有问题,不符合开发规范,看了一下表结构:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
mysql> show create table myabccydf_table; +-----------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | Table | Create Table | +-----------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | myabccydf_table | CREATE TABLE `myabccydf_table` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `item_id` int(11) DEFAULT NULL, `mymum_mydady_sansy_id` int(11) DEFAULT NULL, `quantity` int(11) DEFAULT NULL, `created_at` datetime DEFAULT NULL, `updated_at` datetime DEFAULT NULL, `item_type` varchar(255) NOT NULL, PRIMARY KEY (`id`), KEY `index_myabccydf_table_on_mymum_mydady_sansy_id` (`mymum_mydady_sansy_id`) ) ENGINE=InnoDB AUTO_INCREMENT=2227662255 DEFAULT CHARSET=utf8 | +-----------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ 1 row in set (0.00 sec) |
尝试把各个字段依次带入,分别运行了一下。发现如果不带最后一个字段,那么20多秒就能跑出来;
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
mysql> SELECT `myabccydf_table`.id, -> `myabccydf_table`.item_id, -> `myabccydf_table`.mymum_mydady_sansy_id, -> `myabccydf_table`.quantity, -> `myabccydf_table`.created_at, -> `myabccydf_table`.updated_at -> FROM `myabccydf_table` -> INNER JOIN `ownddeu_mynameac` ON `ownddeu_mynameac`.`id` = `myabccydf_table`.`item_id` -> WHERE (`ownddeu_mynameac`.`published_at` <= NOW() + INTERVAL 0 DAY) -> ORDER BY `myabccydf_table`.`updated_at` desc LIMIT 10 OFFSET 0; (结果略) 10 rows in set (24.30 sec) mysql> |
而带上了最后那个item_type的字段后,需要6,7分钟才能跑出来:
|
1 2 3 4 5 6 7 8 |
mysql> SELECT `myabccydf_table`.* FROM `myabccydf_table` -> INNER JOIN `ownddeu_mynameac` ON `ownddeu_mynameac`.`id` = `myabccydf_table`.`item_id` -> WHERE (`ownddeu_mynameac`.`published_at` <= NOW() + INTERVAL 0 DAY) -> ORDER BY `myabccydf_table`.`updated_at` desc LIMIT 10 OFFSET 0; (结果略) 10 rows in set (6 min 17.34 sec) mysql> |
并且在阿里云和aws,都测试了一下。发现跑的时候,都会造成约40左右的空间降低,在跑完之后,空间迅速恢复。
阿里云:
阿里云的“监控与告警”面板:
阿里云的CLoudDBA的“性能趋势”面板:
aws:
aws起始状态:

aws跑的过程中的状态:

都可以看到,单个线程跑都需要消耗40G左右的临时空间。
那么,当时在阿里云上看到16个active session都跑在create sort index,消耗400多G的临时文件,也就不足为奇了。
但是,为什么这个item_type的字段,一旦带上去了,就要消耗那么多的临时文件呢?一个varchar 255的字段长度,有那么大的威力吗?
和知数堂的徐晨亮聊聊一下,说这个可能和mysql的几种排序方式有关,建议我可以具体分析一下。
要看采用了那种的排序方式,普通的explain已经无法看到,我通过打开设置了optimizer_trace=on,来进一步分析。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
mysql> select @@optimizer_trace; +-------------------------+ | @@optimizer_trace | +-------------------------+ | enabled=on,one_line=off | +-------------------------+ mysql> set session optimizer_trace='enabled=on'; Query OK, 0 rows affected (0.00 sec) mysql> mysql> SELECT `myabccydf_table`.* FROM `myabccydf_table` -> INNER JOIN `ownddeu_mynameac` ON `ownddeu_mynameac`.`id` = `myabccydf_table`.`item_id` -> WHERE (`ownddeu_mynameac`.`published_at` <= NOW() + INTERVAL 0 DAY) -> ORDER BY `myabccydf_table`.`updated_at` desc LIMIT 10 OFFSET 0; (结果略) 10 rows in set (6 min 17.34 sec) mysql> |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 |
mysql> select * from information_schema.optimizer_trace\G; *************************** 1. row *************************** QUERY: SELECT `myabccydf_table`.* FROM `myabccydf_table` INNER JOIN `ownddeu_mynameac` ON `ownddeu_mynameac`.`id` = `myabccydf_table`.`item_id` WHERE (`ownddeu_mynameac`.`published_at` <= NOW() + INTERVAL 0 DAY) ORDER BY `myabccydf_table`.`updated_at` desc LIMIT 10 OFFSET 0 TRACE: { "steps": [ { "join_preparation": { "select#": 1, "steps": [ { "expanded_query": "/* select#1 */ select `myabccydf_table`.`id` AS `id`,`myabccydf_table`.`item_id` AS `item_id`,`myabccydf_table`.`mymum_mydady_sansy_id` AS `mymum_mydady_sansy_id`,`myabccydf_table`.`quantity` AS `quantity`,`myabccydf_table`.`created_at` AS `created_at`,`myabccydf_table`.`updated_at` AS `updated_at`,`myabccydf_table`.`item_type` AS `item_type` from (`myabccydf_table` join `ownddeu_mynameac` on((`ownddeu_mynameac`.`id` = `myabccydf_table`.`item_id`))) where (`ownddeu_mynameac`.`published_at` <= (now() + interval 0 day)) order by `myabccydf_table`.`updated_at` desc limit 0,10" } ] } }, { "join_optimization": { "select#": 1, "steps": [ { "transformations_to_nested_joins": { "transformations": [ "JOIN_condition_to_WHERE", "parenthesis_removal" ], "expanded_query": "/* select#1 */ select `myabccydf_table`.`id` AS `id`,`myabccydf_table`.`item_id` AS `item_id`,`myabccydf_table`.`mymum_mydady_sansy_id` AS `mymum_mydady_sansy_id`,`myabccydf_table`.`quantity` AS `quantity`,`myabccydf_table`.`created_at` AS `created_at`,`myabccydf_table`.`updated_at` AS `updated_at`,`myabccydf_table`.`item_type` AS `item_type` from `myabccydf_table` join `ownddeu_mynameac` where ((`ownddeu_mynameac`.`published_at` <= (now() + interval 0 day)) and (`ownddeu_mynameac`.`id` = `myabccydf_table`.`item_id`)) order by `myabccydf_table`.`updated_at` desc limit 0,10" } }, { "condition_processing": { "condition": "WHERE", "original_condition": "((`ownddeu_mynameac`.`published_at` <= (now() + interval 0 day)) and (`ownddeu_mynameac`.`id` = `myabccydf_table`.`item_id`))", "steps": [ { "transformation": "equality_propagation", "resulting_condition": "((`ownddeu_mynameac`.`published_at` <= (now() + interval 0 day)) and multiple equal(`ownddeu_mynameac`.`id`, `myabccydf_table`.`item_id`))" }, { "transformation": "constant_propagation", "resulting_condition": "((`ownddeu_mynameac`.`published_at` <= (now() + interval 0 day)) and multiple equal(`ownddeu_mynameac`.`id`, `myabccydf_table`.`item_id`))" }, { "transformation": "trivial_condition_removal", "resulting_condition": "((`ownddeu_mynameac`.`published_at` <= (now() + interval 0 day)) and multiple equal(`ownddeu_mynameac`.`id`, `myabccydf_table`.`item_id`))" } ] } }, { "table_dependencies": [ { "table": "`myabccydf_table`", "row_may_be_null": false, "map_bit": 0, "depends_on_map_bits": [ ] }, { "table": "`ownddeu_mynameac`", "row_may_be_null": false, "map_bit": 1, "depends_on_map_bits": [ ] } ] }, { "ref_optimizer_key_uses": [ { "table": "`ownddeu_mynameac`", "field": "id", "equals": "`myabccydf_table`.`item_id`", "null_rejecting": true } ] }, { "rows_estimation": [ { "table": "`myabccydf_table`", "table_scan": { "rows": 25033268, "cost": 392812 } }, { "table": "`ownddeu_mynameac`", "table_scan": { "rows": 2789, "cost": 97 } } ] }, { "considered_execution_plans": [ { "plan_prefix": [ ], "table": "`myabccydf_table`", "best_access_path": { "considered_access_paths": [ { "access_type": "scan", "rows": 2.5e7, "cost": 5.4e6, "chosen": true } ] }, "cost_for_plan": 5.4e6, "rows_for_plan": 2.5e7, "rest_of_plan": [ { "plan_prefix": [ "`myabccydf_table`" ], "table": "`ownddeu_mynameac`", "best_access_path": { "considered_access_paths": [ { "access_type": "ref", "index": "PRIMARY", "rows": 1, "cost": 2.5e7, "chosen": true }, { "access_type": "scan", "using_join_cache": true, "rows": 2092, "cost": 1e10, "chosen": false } ] }, "cost_for_plan": 3.54e7, "rows_for_plan": 2.5e7, "chosen": true } ] }, { "plan_prefix": [ ], "table": "`ownddeu_mynameac`", "best_access_path": { "considered_access_paths": [ { "access_type": "ref", "index": "PRIMARY", "usable": false, "chosen": false }, { "access_type": "scan", "rows": 2789, "cost": 654.8, "chosen": true } ] }, "cost_for_plan": 654.8, "rows_for_plan": 2789, "rest_of_plan": [ { "plan_prefix": [ "`ownddeu_mynameac`" ], "table": "`myabccydf_table`", "best_access_path": { "considered_access_paths": [ { "access_type": "scan", "using_join_cache": true, "rows": 2.5e7, "cost": 1.4e10, "chosen": true } ] }, "cost_for_plan": 1.4e10, "rows_for_plan": 7e10, "pruned_by_cost": true } ] } ] }, { "attaching_conditions_to_tables": { "original_condition": "((`ownddeu_mynameac`.`id` = `myabccydf_table`.`item_id`) and (`ownddeu_mynameac`.`published_at` <= (now() + interval 0 day)))", "attached_conditions_computation": [ ], "attached_conditions_summary": [ { "table": "`myabccydf_table`", "attached": "(`myabccydf_table`.`item_id` is not null)" }, { "table": "`ownddeu_mynameac`", "attached": "(`ownddeu_mynameac`.`published_at` <= (now() + interval 0 day))" } ] } }, { "clause_processing": { "clause": "ORDER BY", "original_clause": "`myabccydf_table`.`updated_at` desc", "items": [ { "item": "`myabccydf_table`.`updated_at`" } ], "resulting_clause_is_simple": true, "resulting_clause": "`myabccydf_table`.`updated_at` desc" } }, { "refine_plan": [ { "table": "`myabccydf_table`", "access_type": "table_scan" }, { "table": "`ownddeu_mynameac`" } ] } ] } }, { "join_execution": { "select#": 1, "steps": [ { "filesort_information": [ { "direction": "desc", "table": "`myabccydf_table`", "field": "updated_at" } ], "filesort_priority_queue_optimization": { "usable": false, "cause": "not applicable (no LIMIT)" }, "filesort_execution": [ ], "filesort_summary": { "rows": 26497152, "examined_rows": 26497152, "number_of_tmp_files": 10287, "sort_buffer_size": 2096864, "sort_mode": "<sort_key, additional_fields>" } } ] } } ] } MISSING_BYTES_BEYOND_MAX_MEM_SIZE: 0 INSUFFICIENT_PRIVILEGES: 0 1 row in set (0.00 sec) ERROR: No query specified mysql> mysql> mysql> mysql> set session optimizer_trace='enabled=off'; Query OK, 0 rows affected (0.00 sec) mysql> |
我们重点看这一部分:
|
1 2 3 4 5 6 7 |
"filesort_summary": { "rows": 26497152, "examined_rows": 26497152, "number_of_tmp_files": 10287, "sort_buffer_size": 2096864, "sort_mode": "<sort_key, additional_fields>" } |
这里的sort_key, additional_fields,说明这个语句,是采用mysql的第二种排序方式。
mysql的排序方式有3种:
- < sort_key, rowid >对应的是MySQL 4.1之前的“原始排序模式”
- < sort_key, additional_fields >对应的是MySQL 4.1以后引入的“修改后排序模式”
- < sort_key, packed_additional_fields >是MySQL 5.7.3以后引入的进一步优化的“打包数据排序模式”
1. 原始排序模式:
根据索引或者全表扫描,按照过滤条件获得需要查询的排序字段值和row ID;
将要排序字段值和row ID组成键值对,存入sort buffer中;
如果sort buffer内存大于这些键值对的内存,就不需要创建临时文件了。否则,每次sort buffer填满以后,需要直接用qsort(快速排序算法)在内存中排好序,并写到临时文件中;
重复上述步骤,直到所有的行数据都正常读取了完成;
用到了临时文件的,需要利用磁盘外部排序,将row id写入到结果文件中;
根据结果文件中的row ID按序读取用户需要返回的数据。由于row ID不是顺序的,导致回表时是随机IO,为了进一步优化性能(变成顺序IO),MySQL会读一批row ID,并将读到的数据按排序字段顺序插入缓存区中(内存大小read_rnd_buffer_size)。
2. 修改后排序模式:
根据索引或者全表扫描,按照过滤条件获得需要查询的数据;
将要排序的列值和用户需要返回的字段组成键值对,存入sort buffer中;
如果sort buffer内存大于这些键值对的内存,就不需要创建临时文件了。否则,每次sort buffer填满以后,需要直接用qsort(快速排序算法)在内存中排好序,并写到临时文件中;
重复上述步骤,直到所有的行数据都正常读取了完成;
用到了临时文件的,需要利用磁盘外部排序,将排序后的数据写入到结果文件中;
直接从结果文件中返回用户需要的字段数据,而不是根据row ID再次回表查询。
3. 打包数据排序模式:
第三种排序模式的改进仅仅在于将char和varchar字段存到sort buffer中时,更加紧缩。
在之前的两种模式中,存储了“yes”3个字符的定义为VARCHAR(255)的列会在内存中申请255个字符内存空间,但是5.7.3改进后,只需要存储2个字节的字段长度和3个字符内存空间(用于保存”yes”这三个字符)就够了,内存空间整整压缩了50多倍,可以让更多的键值对保存在sort buffer中。
我们这个数据库的版本是5.6,所以无法用到第三种排序方式,那么它是怎么选择第二种还是第一种的排序方式呢?
MySQL给用户提供了一个max_length_for_sort_data的参数。当“排序的键值对大小” >max_length_for_sort_data时,MySQL认为磁盘外部排序的IO效率不如回表的效率,会选择第一种排序模式;反之,会选择第二种不回表的模式。
我们当前数据库的max_length_for_sort_data大小为:
|
1 2 3 4 5 6 7 8 9 |
mysql> show variables like '%max_length_for_sort_data%'; +--------------------------+-------+ | Variable_name | Value | +--------------------------+-------+ | max_length_for_sort_data | 1024 | +--------------------------+-------+ 1 row in set (0.00 sec) mysql> |
排序键值对是返回字段+排序字段,注意这里是返回字段,我们是select *,因此包含了myabccydf_table表的所有字段。
|
1 2 3 4 5 6 7 8 9 |
`id` bigint(20) NOT NULL AUTO_INCREMENT, `item_id` int(11) DEFAULT NULL, `mymum_mydady_sansy_id` int(11) DEFAULT NULL, `quantity` int(11) DEFAULT NULL, `created_at` datetime DEFAULT NULL, `updated_at` datetime DEFAULT NULL, `item_type` varchar(255) NOT NULL, `updated_at` datetime DEFAULT NULL, |
我们的库是utf8:
根据mysql的文档:
1. int和bigint:
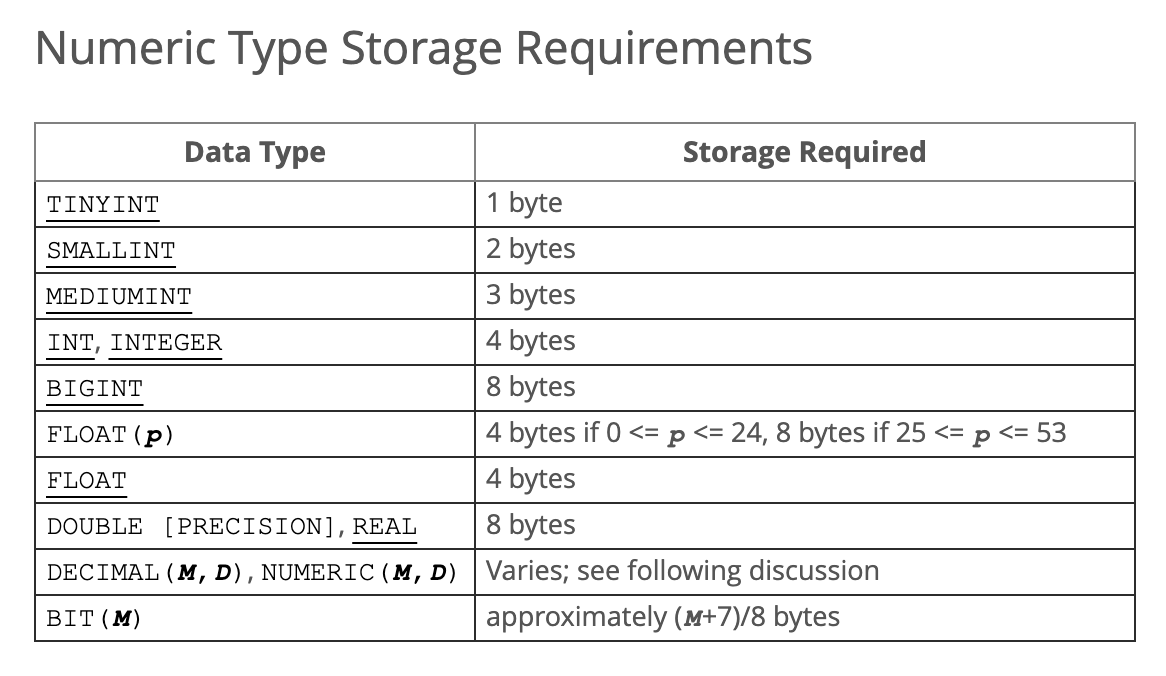
2. datetime:

3. varchar:

因此需要占据排序区的大小为:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
mysql> select version(); +------------+ | version() | +------------+ | 5.6.16-log | +------------+ 1 row in set (0.00 sec) mysql> mysql> select (8+4+4+4+5+5+255*3+5); +-----------------------+ | (8+4+4+4+5+5+255*3+5) | +-----------------------+ | 800 | +-----------------------+ 1 row in set (0.00 sec) mysql> 1 row in set (0.00 sec) |
因此,排序的键值对大小,800,小于max_length_for_sort_data的值1024,mysql会认为磁盘外部的IO效率高于通过rowid回表的效率,因此采用了第二种排序方式。
那么第二种的排序方式,消耗多大的临时空间呢,我们知道,需要排序的内容是“排序列+返回列”,也就是(单个排序列+返回列的大小)*返回的行数,即:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
mysql> select (8+4+4+4+5+5+255*3+5)*26385116; +--------------------------------+ | (8+4+4+4+5+5+255*3+5)*26385116 | +--------------------------------+ | 21108092800 | +--------------------------------+ 1 row in set (0.00 sec) mysql> 大约是20G左右的空间。 那么这20G左右的数据,怎么样在数据库主机上,消耗40G左右空间呢?为什么排序操作完了之后,40G的临时空间又马上释放了呢? 首先说说mysql的外部排序方式,是现在内存中,以sort_buffer_size的大小进行排序,如果能在内存中完成排序,那就不用使用临时文件,如果内存中排不下,那么就需要使用临时文件了。 仍然在filesort_summary部分,我们可以看到: <pre class="lang:default decode:true "> "filesort_summary": { "rows": 26497152, "examined_rows": 26497152, "number_of_tmp_files": 10287, "sort_buffer_size": 2096864, "sort_mode": "<sort_key, additional_fields>" } |
这里可以看到,sort_buffer_size是2096864,这个是mysql里面的设置,number_of_tmp_files是10287,也就是说,在排序的时候,在内存里面排不下,需要用到外部文件,外部文件按照sort_buffer_size的大小,切成了10287个文件,每个大小是2096864。我们把每个临时文件,叫做一个chunk。那么这些chunk的大小,就是需要排序的数据大小,也就是20G,或者按照sort_buffer_size*number_of_tmp_files计算,也是20G左右的大小。
那么这些chunk,每个chunk完成了排序,需要合并成一个大的排序文件,也就是说,需要将10287个文件,总共20G的临时文件,合并成一个大的最终排序结果文件。那么这个文件也是20G,所以零碎的排序文件+合并结果的排序文件,总共大小是40G。
那么这些临时文件,为什么在排序完成的时候,就释放了呢?
临时文件它是在发起filesort的时候,先有mkstemp函数生成一个文件,但是生成之后马上调用unlink删除文件。但是删掉又不close文件,还是保留了文件系统句柄,因此后续的写临时文件的操作,都是基于句柄。
这类似我们打开一个文件,但是另外的进程把这个文件删掉了,但是之前的那个进程,还是操作着这个文件的句柄。可以仍然对这个文件读写,只是我们ls已经看不到这个文件了,但是df -h还是看的空间没释放。只有等到第一个进程关闭了文件句柄,才释放掉了这个文件占据的空间。
所以mysql的用户线程开始操作,那么就一直握着文件句柄,然后在临时文件内完成内存与文件的sort-merge排序操作,完成了操作之后,用户进程可以close掉这个文件句柄,但是又没退出和mysql服务器的连接。
所以就能看到我们看到的现象:就是阿里云上的临时文件的占用,在开始的时候上升,一旦排序结束,就下降了。
好了,到这里,应该就解释了,为什么一个小小的2000多万行的排序,消耗了40多G的临时文件,并且在排序操作完成之后,就立即释放了空间。那么,对应的解决方法,我们有可以随着而来。
改进方式1:
为排序字段添加索引。
改进方式2:
既然是采用了additional_fields的方式进行排序,而这种排序方式由于select了所有字段,导致排序体积过大,那么我不采用additional_fields 的方式,改用rowid的方式:
可以session级别修改max_length_for_sort_data,使得这个值小于800。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
mysql> select @@max_length_for_sort_data; +----------------------------+ | @@max_length_for_sort_data | +----------------------------+ | 1024 | +----------------------------+ 1 row in set (0.00 sec) mysql> mysql> mysql> set session max_length_for_sort_data=100; Query OK, 0 rows affected (0.00 sec) mysql> select @@max_length_for_sort_data; +----------------------------+ | @@max_length_for_sort_data | +----------------------------+ | 100 | +----------------------------+ 1 row in set (0.00 sec) mysql> mysql> SELECT `myabccydf_table`.* FROM `myabccydf_table` -> INNER JOIN `ownddeu_mynameac` ON `ownddeu_mynameac`.`id` = `myabccydf_table`.`item_id` -> WHERE (`ownddeu_mynameac`.`published_at` <= NOW() + INTERVAL 0 DAY) -> ORDER BY `myabccydf_table`.`updated_at` desc LIMIT 10 OFFSET 0; (结果略) 10 rows in set (12.90 sec) mysql> |
可以看到,我们没有修改任何语句,12秒也可以出结果了。
改进方式3:
采用延时关联的方法,这个方法,我们在分页查询的时候,经常用到。需要注意的事,驱动表和关联字段是一个表。
|
1 2 3 4 5 6 7 8 |
SELECT `x`.* FROM `myabccydf_table` x join ( select `myabccydf_table`.id from `myabccydf_table` INNER JOIN `ownddeu_mynameac` ON `ownddeu_mynameac`.`id` = `myabccydf_table`.`item_id` WHERE (`ownddeu_mynameac`.`published_at` <= NOW() + INTERVAL 0 DAY) ORDER BY `myabccydf_table`.`updated_at` desc LIMIT 10 ) t using(id); |
|
1 2 3 4 5 6 7 8 9 10 11 12 |
mysql> SELECT `x`.* FROM `myabccydf_table` x join -> ( -> select `myabccydf_table`.id from `myabccydf_table` -> INNER JOIN `ownddeu_mynameac` ON `ownddeu_mynameac`.`id` = `myabccydf_table`.`item_id` -> WHERE (`ownddeu_mynameac`.`published_at` <= NOW() + INTERVAL 0 DAY) -> ORDER BY `myabccydf_table`.`updated_at` desc LIMIT 10 -> ) t -> using(id); (结果略) 10 rows in set (15.00 sec) mysql> |
总结几条军规,就是:
1. mysql的字段选择要严谨,如字段类型定义长varchar 255,虽然在存放数据的时候,只是放14个字符,但是一旦这个字段被查询到用于排序的时候,就会按照255个字符申请内存。
2. 带order by的查询应该禁止select *操作,而select具体的必要字段。
3. 排序字段和返回字段,建议形成覆盖索引。
本来,到这里,花了一天的时间,已经把问题搞清楚,并且在团队内部进行了分享。但是我并不打算到此结束,接下来我打算做个有趣的实验,同一个问题在aws和阿里云都开了个case,一方面看看哪家服务更专业;另一方面我也想看看云厂商能专业到什么程度,是否能取代专业的DBA,未来企业内部的DBA是否还有生存空间。
于是,我两家云厂商都开了case,咨询为什么一个小小的查询需要消耗40G的临时文件。看看两家对rds的技术问题的处理风格。
需要说明有3点:
1. 这个case没有主动让TAM和研发介入,只是看看一线后台人员的技术水平,或者看看如果仅仅通过开case(这也是大家最简单、最常见的寻求支持的途径),能处理到什么地步。
2. 我后续的评论和感受,仅仅针对于这个case,不代表整体水平。
3. 给了两家厂商一个星期的时间,一般来说,跟case跟一个星期,如果还没结论,那就基本分析不出来了。
我们来看看同一时间线下,两家的不同反应:
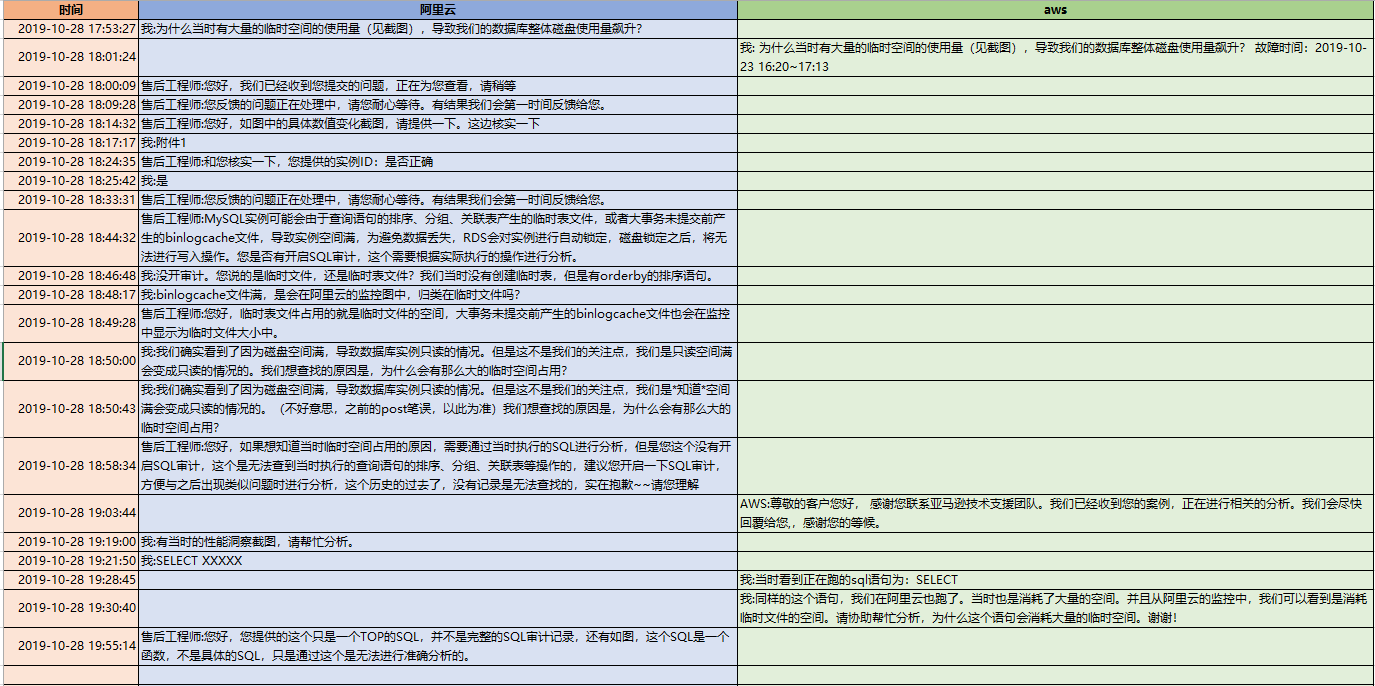



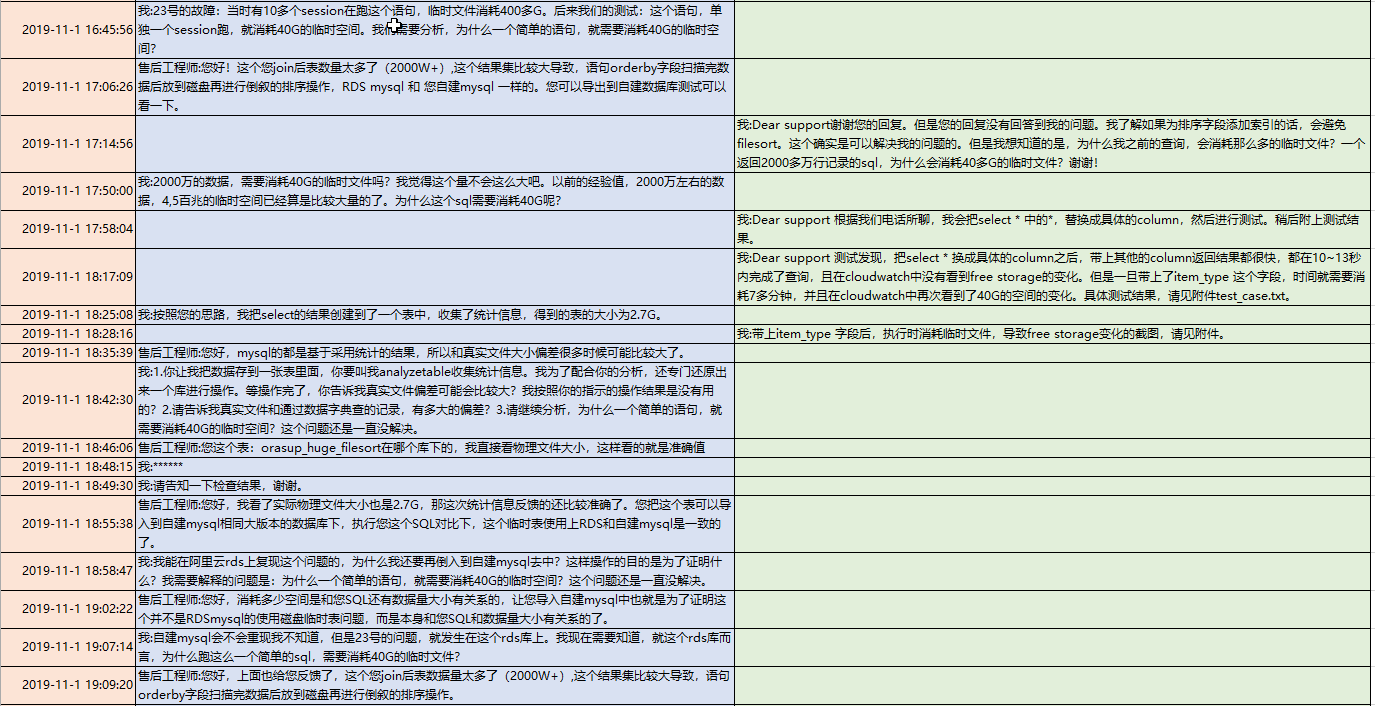

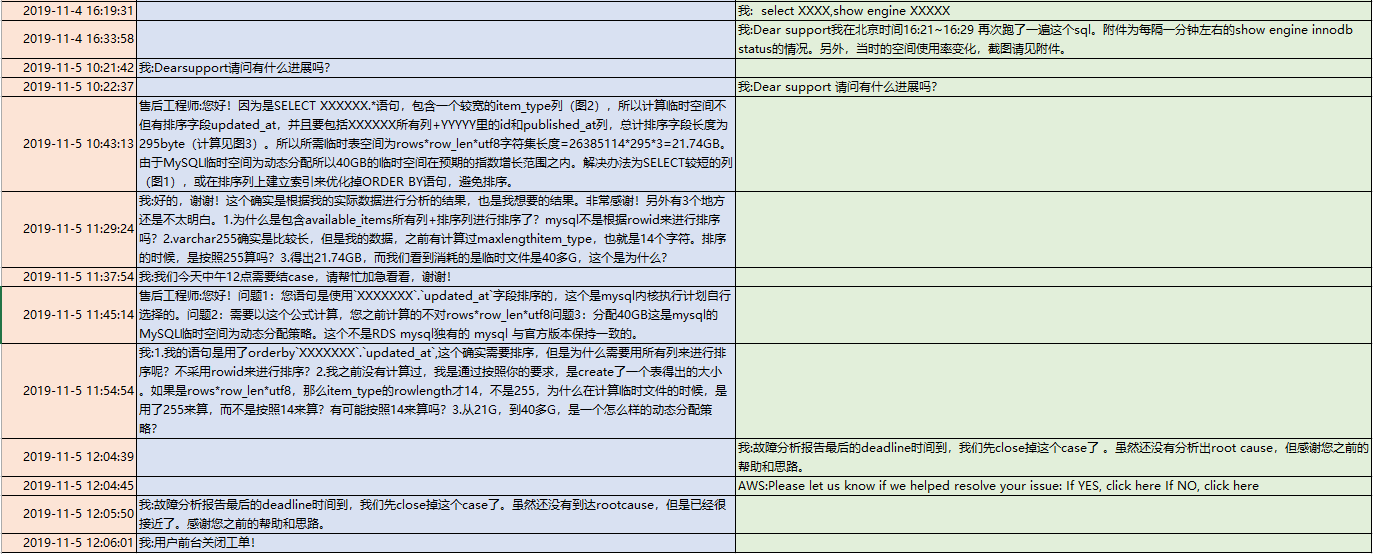
首先说说感受:
1. 阿里云的case的反应非常迅速,回复的很快,也非常的激进。基本没有pending在他手上过夜的。
2. aws的TAM也非常负责任,看到了rds的工单,有主动打电话联系我,询问是否需要帮助。他也主动去追工程师。
3. 阿里云的工程师,一开始是推脱,需要这个需要那个,需要开审计功能,说我没有审计,无法帮我。
4. aws的工程师比较务实,一开始就问我要了表结构和explain的信息。这是一种负责任的态度,是用心在问客户要数据,分析数据的态度。
5. 阿里云的工程师给人的感觉是并不分析用户的数据,不主动向用户要细节,只是给用户一些空对空的指示和建议。其实在请教阿里云之前,我也做过网上的搜索,我发现他告诉我的那些话,我都在网上看到过。
6. 阿里云的工程师,那种风格给人感觉是先拿着锤子到处砸,运气好的话砸到了故障根因,运气不好的话,看能否砸晕客户,因为他告诉我的一些结论,不太经得起推敲。如果我是一个很着急需要得到一个结果去写报告的人,往往他这种风格可以满足到我。可惜我这次不是这样,我去细细推敲了他的分析,我发现他的一些计算是错误的。他试图绕晕我,如果我不坚定,很容易在过程中接收了他的结论。
7. aws的工程师比较务实的地方,不仅仅体现在他一开始问我要了表结构和explain,还很坦诚的打电话告诉我,这个问题是他能力范围之外的,但是由于我们是企业用户,他会用best effort来帮助我们。而且,在从20G的临时文件,为什么会到40G的推理上,他在电话中也比较接近真相。他提到了有临时的小文件,和会有一个汇总的大文件。只是还没想到两路外部排序算法和多路外部排序算法。
8. aws的工程师,对于能力之外的问题,反应比较慢,远远没有阿里云的工程师更新case来的积极主动,我往往很久都看不到他在case上的更新。所以我也不知道他的分析进度和状态如何。这一点是让我担心的。
9. 最终的结果,在一周之内,两家都没分析出根因。阿里云更接近一点,他根据字段长度去算了,但是算的方法不对,结论是错误的。utf8,一个字符占3个字节,只是针对字符型的,所以算的时候,应该是(8+4+4+4+5+5+255*3+5),而不是(8+4+4+4+5+5+256+4+5)*3,不应该把其他类型也乘以3;另外排序的第二种算法应该是排序列+返回列,阿里云是把两个表的所有出现过的列计算了。

阿里云只是数字上比较接近。
10. 如果要让我选一家,我可能会选aws,因为他的诚恳和务实。我买的是服务,不想被忽悠。
然后说说结论:
目前云厂商的专线技术水平,还不能达到专业DBA的水平,就云厂商的一线工程师而言,可能有能力处理一般的rds的功能问题,但是进一步的根因查找,就无能为力了。因此企业内部的DBA还是有一定的市场。我之前写过一个比较悲观的dba将死,云架构师即将到来,但是现在来看,可能没死的那么快,至少在5年内,还不会迅速消失。
关键还是看公司对数据库的重视程度。是否有足够的人力,是否需要精细化运维,是否每次故障都需要分析根因?还是过去了就没事?下次再掉同样坑里面,大不了重启解决99%的IT问题。

参考:
MySQL排序内部原理探秘
MySQL · 引擎特性 · 临时表那些事儿
Data Type Storage Requirements
Unicode Support
MySQL 5.6 Reference Manual – ORDER BY Optimization
MySQL 5.1 Reference – Chapter 7. Optimization
2条评论
写的深入浅出,您不仅oracle水平高,mysql也已经是高手了。
云服务商的一线客服人员是没有高手的,他们只是想尽快把单子结束了,好满足绩效考核。