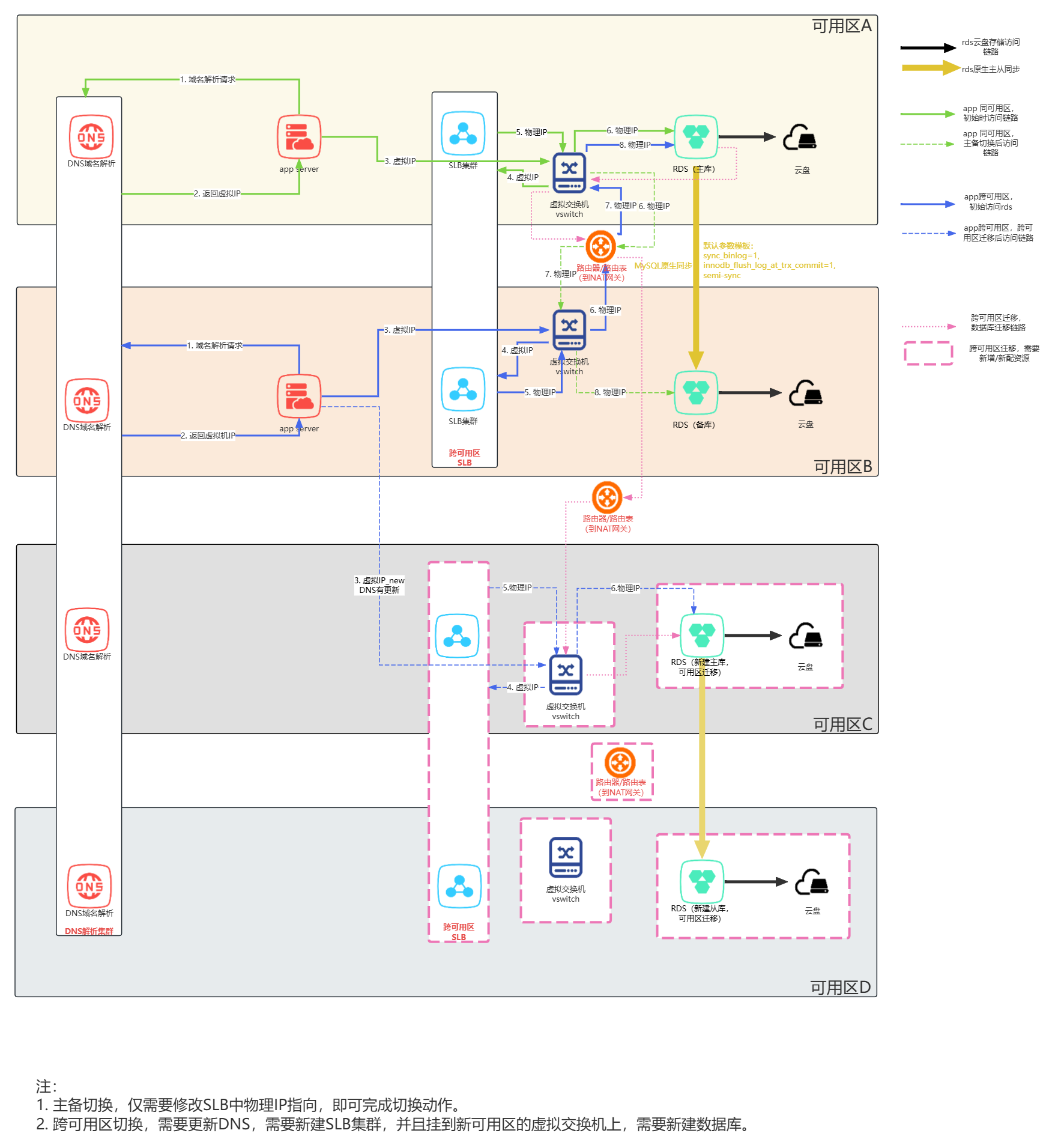
高清PDF:阿里云主备切换和跨可用区迁移示意图
高清VISIO:阿里云主备切换和跨可用区迁移示意图
先说结论:阿里云说的发生切换时(不管是主备切换还是跨可用区切换),影响时间是30秒内,这个是基本成立的。
测试是每种场景测试4~5次,观察其平均效果。
| 主备库切换 | 迁移可用区 | |
MySQL |
只读:1秒 |
只读:10~20秒 |
PostgreSQL |
断联:1秒只读:8~9秒正常读写:5~30秒断联:1秒只读:8~9秒
汇总:影响20秒左右 |
只读:8~9秒断联:1秒正常读写:5秒断联:1秒只读:15秒~30秒
汇总:影响约30秒 |
MongoDB(非分片) |
只读:25秒断联:12秒汇总:影响37秒 |
有条件的只读(需要执行rs.slaveOk()才能只读):16~26秒断联:2秒有条件的只读(需要执行rs.slaveOk()才能只读):4~11秒汇总:影响40秒内 |
(一)MySQL:
1. 运行压测语句:
|
1 2 3 4 5 6 7 8 9 10 11 |
while true do RUN_FLAG=`ps -ef |grep sysbench |grep run |grep -v grep |wc -l` if [ ${RUN_FLAG} -lt 1 ]; then sysbench oltp_read_write --mysql-host=xxxxxxxxxx.rds.aliyuncs.com --mysql-port=3306 --mysql-user=myuser --mysql-password=mypassword --mysql-db=testdb --tables=32 --table-size=10000000 --threads=32 --time=6000 --report-interval=1 run echo "====== `date` ======The sysbench process is STOP." else echo "====== `date` ======The sysbench process is RUNNING." fi sleep 1 done |
2. 运行查询语句:
|
1 2 3 4 5 6 |
while true do mysql -hxxxxxxxxxx.rds.aliyuncs.com -umyuser -Dtestdb -pmypassword -e"select count(*) from orasup_test1" echo "========***************==========`date`========*************=====" sleep 0.5 done |
3. 运行dml语句:
|
1 2 3 4 5 6 |
while true do mysql -hxxxxxxxxxx.rds.aliyuncs.com -myuser -Dtestdb -pmypassword -e"update orasup_test1 set b=now() where a=1" echo "========***************==========`date`========*************=====" sleep 0.5 done |
观测在有压力的情况下,mysql进行主备切换,和跨可用区切换,受影响的时间范围。
(二)PostgreSQL
1. 运行压测语句:
|
1 2 3 4 5 6 7 8 9 10 11 |
while true do RUN_FLAG=`ps -ef |grep pgbench |grep -v grep |wc -l` if [ ${RUN_FLAG} -lt 1 ]; then echo "====== `date` ======The sysbench process is STOP." nohup pgbench -c 32 -j 2 -T 6000 -h xxxxxxxxxx.rds.aliyuncs.com -U myuser testdb & else echo "====== `date` ======The sysbench process is RUNNING." fi sleep 1 done |
2. 运行查询语句:
|
1 2 3 4 5 6 |
while true do psql -h xxxxxxxxxx.rds.aliyuncs.com -U myuser -d testdb -c "select count(*) from orasup_test1" echo "========***************==========`date`========*************=====" sleep 0.5 done |
3. 运行dml语句:
|
1 2 3 4 5 6 |
while true do psql -h xxxxxxxxxx.rds.aliyuncs.com -U app_rw -d myuser -c "update orasup_test1 set b=now() where a=1" echo "========***************==========`date`========*************=====" sleep 0.5 done |
观测在有压力的情况下,pg进行主备切换,和跨可用区切换,受影响的时间范围。
(三)MongoDB
1. 运行压测语句:
|
1 2 3 4 5 6 7 |
while true do echo "========***************==========`date`========*************=====" /data/mongodb/4.2.0/bin/mongo --host xxxxxxxxxx.rds.aliyuncs.com --port 3717 testdb --username myuser --password 'mypassword' --authenticationDatabase "admin" --quiet --eval 'db.myNewCollection.updateMany({ name: "User_J" }, { $set: { mytime: new Date() } })' echo "========***************========== BIG TRX ========*************=====" sleep 0.5 done |
2. 运行查询语句:
|
1 2 3 4 5 6 7 |
while true do echo "========***************==========`date`========*************=====" dig xxxxxxxxxx.rds.aliyuncs.com |grep "IN A" /data/mongodb/4.2.0/bin/mongo --host xxxxxxxxxx.rds.aliyuncs.com --port 3717 testdb --username myuser --password 'mypassword' --authenticationDatabase "admin" --quiet --eval 'db.myCollection.find({name:"Bob"})' sleep 1 done |
3. 运行dml语句:
|
1 2 3 4 5 6 7 |
while true do echo "========***************==========`date`========*************=====" dig xxxxxxxxxx.rds.aliyuncs.com |grep "IN A" /data/mongodb/4.2.0/bin/mongo --host xxxxxxxxxx.rds.aliyuncs.com --port 3717 testdb --username myuser --password 'mypassword' --authenticationDatabase "admin" --quiet --eval 'db.myCollection.updateOne({ name: "Bob" }, { $set: { mytime: new Date() } })' sleep 1 done |
观测在有压力的情况下,mongodb进行主备切换,和跨可用区切换,受影响的时间范围。
这里为什么rds pg做主备切换的时候,会断联两次,且中间有可读写的情况。经过向阿里云同学的请教得知:
rds pg,首先ha切换分为两种场景,一种是被动HA切换,另一种是主动HA切换:
对于被动HA切换的场景:
1. 当探测到主节点不可用时,把slb后端ip切换为从节点ip
2. 对老主节点进行 demote(demote 会重启实例,保证所有存量连接断开)
3. 对老从节点进行 promote
所以被动HA切换的情况下是一次断连。
对于主动HA切换的场景:
1. 检查主备复制延迟,由于主动HA切换属于运维动作,需要保证主备0延迟从而避免数据丢失
2. 当检查到主备复制有延迟的情况下,对主节点设置只读并kill session(第一次断连)并等待30s
3. 当主备延迟为0之后把主节点关闭只读并下发HA切换
4. 把slb后端ip切换为从节点ip
5. 对老主节点进行 demote(demote 会重启实例,保证所有存量连接断开,第二次断连)
6. 对老从节点进行 promote
所以主动HA切换且主备有延迟的情况下,会有两次断连,目前是避免数据丢失同时保证切换的成功率,避免有一点延迟的情况下HA始终无法切换导致影响用户的运维动作。
因此,我的测试场景中:
