某天,应用程序突然挂了,程序中报错连不上数据库。登录数据库主机后,发现sqlplus也登录不了,登录时,sqlplus长时间没有响应,检查alertlog只是发现半小时前检测到一个deadlock,没有其他的报错信息。心想oracle检测到deadlock能自动解锁,因此一开始没怀疑到是因为deadlock的原因,由于登录不上数据库,为了尽快的回复业务,停掉应用程序,杀掉ps -ef |grep LOCAL=N的进程后,再次能登录数据库,重启了数据库,再次启动应用,回复正常。
追溯原因时,一开始是怀疑系统的内核参数设置不正确,导致主机资源耗尽,因此无法sqlplus登录。但是检查了一遍主机的内核参数,发现均正常。主机的syslog同样也没发现异常。奇怪,为什么会出现挂死的现象?请教了老网虫白鳝后,才明白了某些版本的oracle检查到deadlock后会触发一个关于deadlock的bug,导致enqueue hash chain的parent latch被hold住,然后在做SYSTEM DUMP的时候可能产生LATCH死锁,这个时候可能hang住,时间可能是在几秒钟,也有可能是几小时。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
…… ARC0: Evaluating archive log 3 thread 1 sequence 36918 ARC0: Beginning to archive log 3 thread 1 sequence 36918 Creating archive destination LOG_ARCHIVE_DEST_1: '/arch/arch_1_36918.arc' Thu Jan 31 15:59:13 2008 ARC0: Completed archiving log 3 thread 1 sequence 36918 Thu Jan 31 16:05:30 2008 Thread 1 advanced to log sequence 36920 Current log# 1 seq# 36920 mem# 0: /dev/vg_ora1/rredo_256m_01 Current log# 1 seq# 36920 mem# 1: /dev/vg_ora2/rredo_256m_11 Current log# 1 seq# 36920 mem# 2: /dev/vg_ora3/rredo_256m_21 Thu Jan 31 16:05:30 2008 ARC1: Evaluating archive log 4 thread 1 sequence 36919 ARC1: Beginning to archive log 4 thread 1 sequence 36919 Creating archive destination LOG_ARCHIVE_DEST_1: '/arch/arch_1_36919.arc' Thu Jan 31 16:05:32 2008 ORA-000060: Deadlock detected. More info in file /oracle/app/oracle/admin/sd168/udump/sd168_ora_14652.trc.---- 注意此处 Thu Jan 31 17:00:11 2008 ARC1: Completed archiving log 4 thread 1 sequence 36919 Thu Jan 31 17:00:14 2008 SMON: Parallel transaction recovery tried Thu Jan 31 17:02:34 2008 Thread 1 advanced to log sequence 36921 Current log# 2 seq# 36921 mem# 0: /dev/vg_ora1/rredo_256m_02 Current log# 2 seq# 36921 mem# 1: /dev/vg_ora2/rredo_256m_12 Current log# 2 seq# 36921 mem# 2: /dev/vg_ora3/rredo_256m_22 Thu Jan 31 17:02:34 2008 ARC0: Evaluating archive log 1 thread 1 sequence 36920 ARC0: Beginning to archive log 1 thread 1 sequence 36920 Creating archive destination LOG_ARCHIVE_DEST_1: '/arch/arch_1_36920.arc' ARC0: Completed archiving log 1 thread 1 sequence 36920 …… |
进一步检查这个deadlock的trace文件:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 |
/oracle/app/oracle/admin/sd168/udump/sd168_ora_14652.trc Oracle9i Enterprise Edition Release 9.2.0.6.0 - 64bit Production With the Partitioning, OLAP and Oracle Data Mining options JServer Release 9.2.0.6.0 - Production ORACLE_HOME = /oracle/app/oracle/product/9.2.0 System name: HP-UX Node name: sd_db01 Release: B.11.11 Version: U Machine: 9000/800 Instance name: sd168 Redo thread mounted by this instance: 1 Oracle process number: 590 Unix process pid: 14652, image: oracle@sd_db01 (TNS V1-V3) *** 2008-01-31 16:05:32.480 *** SESSION ID:(465.37272) 2008-01-31 16:05:32.403 DEADLOCK DETECTED Current SQL statement for this session: delete eips_corporation corp where corp.corpid=:1 The following deadlock is not an ORACLE error. It is a deadlock due to user error in the design of an application or from issuing incorrect ad-hoc SQL. The following information may aid in determining the deadlock: Deadlock graph: ---------Blocker(s)-------- ---------Waiter(s)--------- Resource Name process session holds waits process session holds waits TM-0000872c-00000000 590 465 SX SSX 581 281 SX SSX -------注意此处 TM-0000872c-00000000 581 281 SX SSX 590 465 SX SSX session 465: DID 0001-024E-0000003F session 281: DID 0001-0245-0000002E session 281: DID 0001-0245-0000002E session 465: DID 0001-024E-0000003F Rows waited on: Session 281: obj - rowid = 00008762 - AAAIdiACGAAAAAAAAA (dictionary objn - 34658, file - 134, block - 0, slot - 0) Session 465: obj - rowid = 00008762 - AAAIdiACGAAAAAAAAA (dictionary objn - 34658, file - 134, block - 0, slot - 0) Information on the OTHER waiting sessions: Session 281: pid=581 serial=53477 audsid=7366710 user: 54/EICP O/S info: user: eicp, term: unknown, ospid: , machine: sd-oam01 program: JDBC Thin Client application name: JDBC Thin Client, hash value=0 Current SQL Statement: delete eips_corporation corp where corp.corpid=:1 End of information on OTHER waiting sessions. =================================================== PROCESS STATE ------------- Process global information: process: c0000001991a1720, call: c0000001a57bcfd8, xact: c00000019bfbc5b0, curses: c0000001993bfd88, usrses: c0000001993bfd88 ---------------------------------------- SO: c0000001991a1720, type: 2, owner: 0000000000000000, flag: INIT/-/-/0x00 (process) Oracle pid=590, calls cur/top: c0000001a57bcfd8/c0000001a57bcfd8, flag: (0) - int error: 0, call error: 0, sess error: 0, txn error 0 (post info) last post received: 197 0 4 last post received-location: kslpsr last process to post me: c0000001990e5be0 1 6 last post sent: 0 0 16 last post sent-location: ksasnd last process posted by me: c0000001990e5be0 1 6 (latch info) wait_event=0 bits=10 holding c0000001c1a4d458 Parent+children enqueue hash chains level=4 -------注意此处 Location from where latch is held: ksqcmi: kslgpl: Context saved from call: 0 state=busy recovery area: Dump of memory from 0xC0000001990E4628 to 0xC0000001990E4638 …… |
检查addr为c0000001c1a4d458的latch:
|
1 2 3 4 5 |
SQL> select name from v$latch where addr=upper('c0000001c1a4d458'); NAME ---------------------------------------------------------------- enqueue hash chains |
确实我们看到了enqueue hash chain。enqueue hash chain是用于保护每一个library cache中的hash bucket。
(这里借用一下eygle的图说明一下library cache的结构)
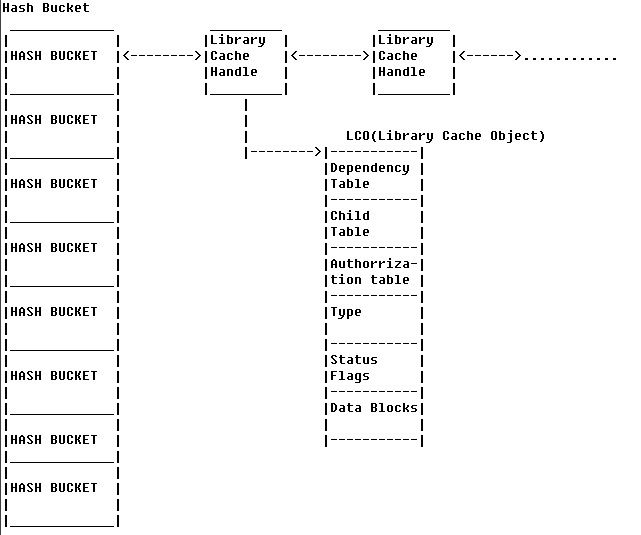
由于parent latch被HOLD了,所有对数据库library cache加锁的操作都无法进行,而sqlplus登录的时候要申请AUDSES$的SEQUENCE,因此sqlplus无法登录,同理所有的应用程序也无法登录——应用程序挂死。
在metalink上也确认了这个bug:2530125
可是,在第二天下午,再次出现的由于deadlock导致数据库挂死的问题,检查alertlog发现在很早之前已经有deadlock的现象,为何系统会频繁的出现deadlock?
根据deadlock的trace文件,根据deadlock graph的wait的模式是SSX,这就很有可能是外键没加索引造成。检查相关语句中的外键,靠!确实是外键没加索引。
对外键增加索引后,系统正常运行一周,不再发生死锁,也不再发生挂死现象。至此问题解决。回顾问题:由于外键没加索引–引起死锁–触发bug2530125–enqueue hash latch–无法登录–程序挂死。